本节主要是介绍了文本聚类,使用基础的bag of words来获取特征,在过程中提到了一些处理文本的基本方法,包括特征提取的tfidf等等。其他高级的主题在后面的章节会提到。这里我们考虑中文的使用,在分词上选用jieba分词包。。这里数据集和问题是参考了书籍《building machine learning system with python》,建模过程和分析属于个人见解,请批判阅读。
目录
1、简单分类器
首先我们导入一些我们需要使用的库。这里主要是使用python,以及它的一些包,主要是numpy、scipy、sklearn等等,绘图使用matplotlib,这里我个人习。我们首先简单的使用jieba分词包和sklearn.feature_extraction下面的text库进行基础的文本特征处理,作为一个引入。
import numpy as np
from matplotlib import pyplot as plt
import pandas as pd
import jieba
import re
import os
DIR = '../../Wiki/_posts/notes'
%matplotlib inline
import seaborn as sns
# styles = ["white", "dark", "whitegrid", "darkgrid", "ticks"]
sns.set(style="darkgrid")
def clean_text(data):
# delete the html, website and mathjax
d = re.sub('<.*?>','', data)
d = re.sub('\$\$.*?\$\$','', d)
d = re.sub('\(http.*?\)','', d)
d = re.sub('\{.*?\}','', d)
# delete the numbers and other space
# pattern ='[\d\s,:#\*\.()]'
pattern ='[\s]'
d = re.sub(pattern, ' ', d)
d = re.sub('---.*?---','', d)
#d = re.sub('[\u4E00-\u9FA5]+','', d) save only the chinese
return d
from sklearn.feature_extraction import text
subpaths = [i for i in os.listdir(DIR)] #['PRML/', 'configuration/']
# print subpaths
contents = []
filenames = []
for subpath in subpaths:
for filename in os.listdir('/'.join([DIR, subpath])):
data = open('/'.join([DIR, subpath, filename])).read()
seg_list = jieba.cut(clean_text(data), cut_all=False)
seg_list = list(seg_list)
contents.append(' '.join(seg_list))
filenames.append(filename)
# vectorizer the contents
stop_words = ('and','on', 'off', '2m', 'ab', u'一下', u'一个', u'一些', u'一点', u'一种',u'目录',
u'其中', u'其他', u'其实', u'从而', u'他们', u'以及')
vectorizer = text.CountVectorizer(min_df=2, max_df=0.7,stop_words=stop_words)
# print content
# print vectorizer
X = vectorizer.fit_transform(contents[17:28])
names = vectorizer.get_feature_names()
print 'the nums of the features: {0}; the lens of contents {1}'.format(len(names),len(contents))
# print len(set(' '.join(contents).split()))
# print ' '.join(names)
输出结果为:the nums of the features: 678; the lens of contents 36
对于特定的文本,我们做了一些特定的预处理,比如这些文本是博客,为了仅通过文本内容分析,我们通过d = re.sub('---.*?---','', d)去掉了博客开始的标题标签(在实际web中,web的tag可能是重要的特征,不需要去掉。),以及文章中的所有数学公式(markdown语法)等等。此外,需要注意以下几个问题:
- 我们也考虑了一部分停用词,这里只是随便给了几个词语而已,我们可以从网上下载一些停用词库。
- 在sklearn的text中,他最终选择的特征都是单词,而单个字都被舍去了,这跟构成token的正则表达式,默认的正则表达式(
token_pattern=u'(?u)\\b\\w\\w+\\b')是选择两个或者两个以上的字符(标点符号是被忽略的,仅仅当作token的分割符),因此在预处理的时候,标点符号是可以不考虑的。 - 在一些处理中,需要考虑字符集,可以从网上找到对应的字符集进行清洗,比如只考虑中文,可以使用
d = re.sub('[\u4E00-\u9FA5]+','', d) - 参数ngram_range是一个需要注意的参数,自己试一下不同参数看看feature_names就知道怎们回事了;
- 参数binary默认是否,如果是真,那么所有非零的计数将被设置成1。这对于离散的只针对二值事件而非整数计数的概率模型很有用。
- 对于min_df等参数,可以查看接口,都比较容易理解,不再赘述。
这种直接把文章根据单词是否存在于文章里或在文章出现的次数作为文章的特征,称之为bag of words。接下来,我们简单的用余弦值来表示各个文章之间的相似度,如下图所示:
d = X.toarray()
norm = np.linalg.norm(d,axis=1).reshape((d.shape[0],1))
d = np.dot(d, d.T) / np.dot(norm, norm.T)
sns.heatmap(d, annot=True, center=0, cmap='coolwarm') # RdBu_r coolwarm
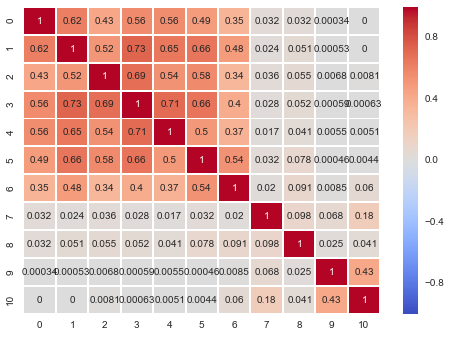
可以看到,PRML系列之间的相关性还是比较明显的。在此之后,我们还需要引入一些文本处理的方式。如果是英文的,可能时态的变换也有影响,可以使用nltk里s=nltk.stem.SnowballStemmer('english')来清洗这些英文单词,中文的话就不需要考虑了。
2、TFIDF
此外,我们考虑一种很常用的方法——term frequency – inverse document frequency (TF-IDF)。TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:\(TF * IDF\),TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。
IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别于其它类文档。这就是IDF的不足之处. 在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)
对于在某一特定文件里的词语\(t_i\) 来说,它的重要性可表示为:\(tf_{i,j} = \frac{n_{i,j}}{\sum_k n_{k,j}}\),以上式子中 \(n_{i,j}\) 是该词在文件\(d_j\)中的出现次数,而分母则是在文件\(d_j\)中所有字词的出现次数之和。逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到: \(idf_i = \log \frac{\mid D \mid }{\mid (j: t_i \in d_j) \mid}\), 其中\(\mid D \mid\):语料库中的文件总数; \(\mid (j: t_i \in d_j) \mid\) :包含词语 \(t_i\) 的文件数目(即 \(n_{i,j} \neq 0\)的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用\(1 + \mid (j : t_i \in d_j) \mid\)。
然后, \(tf \ idf_{i,j} = tf_{i,j} \times idf_{i}\),某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
那么TFIDF怎么用呢?简单的用法是根据TFIDF值,选择合适的词语特征,另外一种是使用向量空间模型的时候,权重不采用词语出现的次数,而采用TFIDF值来作为词向量的值。下面是一个例子:
tfidf = text.TfidfVectorizer(min_df=2, max_df=0.7, stop_words=stop_words)
Xt = tfidf.fit_transform(contents[17:28])
d = Xt.toarray()
norm = np.linalg.norm(d,axis=1).reshape((d.shape[0],1))
d = np.dot(d, d.T) / np.dot(norm, norm.T)
sns.heatmap(d, annot=True, center=0, cmap='coolwarm') # RdBu_r coolwarm
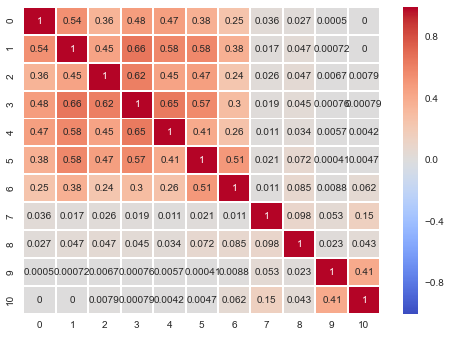
从主对角线上,可以看出大致可以分割为两个类别,不过还是不明显。那么我们总结一下处理的基本流程:
- 1、清理文本(比如标点等等),获取分词后文本;
- 2、删除停用词、以及出现次数太多或者太少的词语;
- 3、记录词频,选择合适的计算框架,比如TFIDF;
这里简单的总结一下bag-of-words的不足:
- 1、没有考虑单词之间的相关性,比如”Car hits wall” 和 “Wall hits car”用这种方法是特征向量是一致的;
- 2、无法刻画否定意义,比如”I will eat icecream” 和 “I will not eat ice cream” 的特征向量是非常相似的;
- 3、完全无法适应拼写错误的单词
3、聚类可视化
接下来,我们使用简单的聚类方式进行可视化。这里我们虽然已经手动分成了两个类别,但是实际文本之间还是有很多交叉的内容。另外,为了可视化,我们使用了PCA降维到2维来可视化一些kmeans的结果。注意,这里为了方便,都直接使用了fit_tranform。
from sklearn import cluster
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_data = pca.fit_transform(d)
tfidf = text.TfidfVectorizer(min_df=2, max_df=0.7, stop_words=stop_words)
Xt = tfidf.fit_transform(contents)
d = Xt.toarray()
param = [{'model':cluster.KMeans(n_clusters=3),
'title':'KMeans'},
{'model':cluster.SpectralClustering(n_clusters=3),
'title':'SpectralClustering'}]
fig, axes = plt.subplots(ncols=2, nrows=1,figsize=(10,5))
for n, ax in enumerate(axes.ravel()):
# plt.figure(figsize=(8, 3))
cluster = param[n]['model']
k_data = cluster.fit_predict(d)
ax.scatter(pca_data[:,0], pca_data[:,1], c=['rgb'[i] for i in k_data], s=50)
ax.set_title(param[n]['title'])
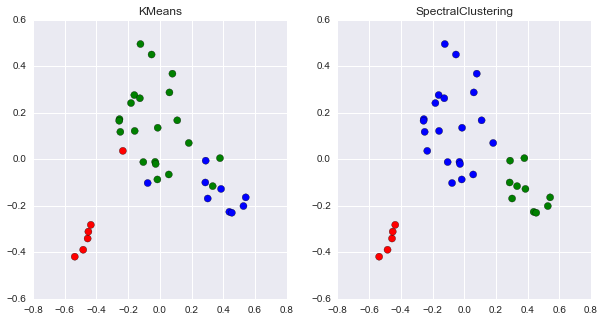
注意:这里没有使用Pipeline,可以在其它过程中尝试使用。这里简单的可视化之后,我们还需要对文本做进一步的分析和考虑。换句话说,我们已经找到了聚类的类别,那么这一类究竟是什么呢?我们还记得IF-IDF值,这个值越大,说明这个文章中的词越具有区分度。那么,我们可以把这一类下文章的词语拿出来看一看:
sub_content2 = [contents[n] for n,i in enumerate(k_data) if i==2]
sub_data_2 = d[k_data==2,:]
sum_sub = sub_data_2.max(axis=0)
print [tfidf.get_feature_names()[n] for n,j in enumerate(sum_sub) if j > 0.4*sum_sub.max()]
print [filenames[n] for n,i in enumerate(k_data) if i==2]
结果如下:
[u'boltzmann', u'by', u'data', u'deep', u'engineering', u'feature', u'for', u'introduction', u'learning', u'library', u'nets', u'of', u'science', u'the', u'you']
['2014-9-26-Discover_Feature_Engineering.md', '2014-10-12-free-data-science-books.md', '2014-12-31-Deep_learning_Reading_List.md', '2014-9-2-resource_of_machine_learning_programme_language.md', '2014-9-22-Reading_lists_for_new_LISA_students.md']
当然,这里只是举一个例子,这种查看主题的方式也未必是合理的。因为我们发现data这个词语在多个聚类中均出现次数很多。而这里,对于参数min_df=2, max_df=0.7影响是非常大的,决定了很多特征的差异性,也需要不断的调整,以得到最合适的聚类结果。