本篇主要是神经网络相关知识。笔记分两部分,这是第二部分:简单的概述不同的神经网络模型。
注:本文仅属于个人学习记录而已!参考Chris Bishop所著Pattern Recognition and Machine Learning(PRML)以及由Elise Arnaud, Radu Horaud, Herve Jegou, Jakob Verbeek等人所组织的Reading Group。
目录
1、卷积神经网络
在这里我们我们已经有一篇文章,这里从数理层面再简单介绍下。结合第一部分,卷积神经网络(convolutional neural network)是利用模型特性来处理掉这些输入的波动而获得不变性特征,由Le Cun提出,目前广泛的应用于图像数据。
这里就不再赘述卷积层和子抽样层的概念了,只是简单的说一些事情。对于图像的输入,使用全连接的话,就忽略了像素点之间的相关性非常大这个问题,现在计算机视觉领域根据这个属性从图像的一部分来提取局部特征(local feature)用于后面的分类或者其他应用。另外,需要注意到图像某个区域的局部特征在别的区域也会倾向于的有用。根据这些特性,卷积神经网络发展出三个核心概念:局部接受野(local receptive fields),权值共享(weight sharing)和子抽样(subsampling)。它的具体结构如下:
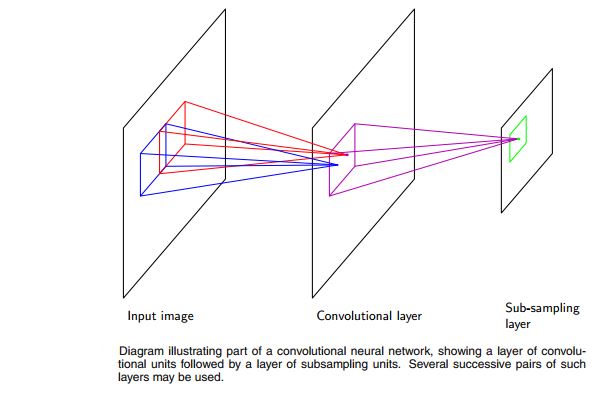
对于权值共享(weight sharing)主要也是通过限制局部的权重相等来降低模型复杂度。而这里考虑的是软权值共享(soft weight sharing),即使得局部权重倾向于相等,这样使得权值组的分配、每个组的权值均值和分布都是可以由网络学习的。就目前来看,CNN的整体结构没有变化,但是在训练过程中,融合了一些其他的知识,比如normalization等等,这些都需要查阅更多的资料。另外,书本上提到了CNN的正则化,这里使用了很多后面要讲到的知识,没有细看。不过,CNN本身其实是不需要做正则化的,毕竟正则化的是为了解决参数过多而带来的过拟合,而在CNN中,已经通过权值共享和子抽样大幅度的降低了参数个数。此外,关于CNN的BP推导等过程,也需要参考其他文档。
2、混合密度网络
在监督式学习中,我们的目标是学习到条件分布\(p(t \mid x)\),但是实际中可能是多峰分布,使得采用高斯分布假设得到的预测结果都比较差。一个inverse的问题是,前向问题(forward problem)的时候,即给定角度的时候,最终位置就是固定的。但是,反过来(反向问题,inverse problem),如果最终位置固定了,角度却不唯一。下图是一个训练的例子,正向训练的时候,得到不错的结果,但是颠倒输入和输出,学习的结果就很差。
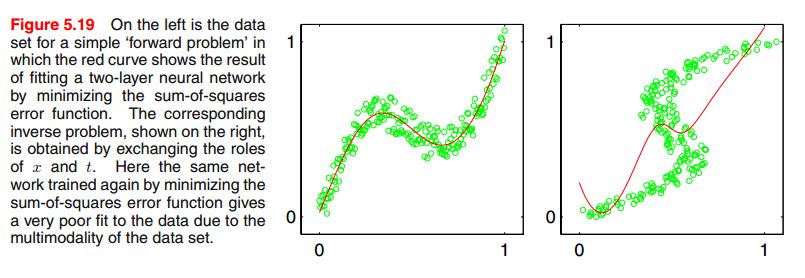
在文章中,主要是展示了为什么有这种结果。即我们采用混合多个高斯分布来拟合目标分布,即混合密度网络(Mixture Density Networks),如下:
\[p(t \mid x) = \sum^K_{k=1} \pi_k(x) N(t \mid \mu_k(x), \sigma_k^2(x))\]这是异方差模型(heteroscedastic model)的一个例子,因为这里的噪声方差是输入向量x的函数。最后,我们得到误差函数如下:
\[E(w) = - \sum^N_{n=1} \ln ( \sum^k_{k=1} \pi_k(x_n,w) N(t_n \mid \mu_k(x_n, w), \sigma^2_k(x_n, w)) )\]之后还是用梯度下降求解。具体推导,也没有细看。这样的模型,得到之后,可以很容易的计算分布的均值和方差,以及可视化分布情况。
3、贝叶斯神经网络
目前为止,我们的讨论都集中在最大似然法求取神经网络参数,而正则化的最大似然也可以认为是MAP(最大后验概率)。而贝叶斯方法,应该是为了预测精度而优化参数分布。然而由于是非凸的,所以得到的分布也可能是局部最优解。后面会提到一种基于方差解释的方法用来求解贝叶斯神经网络。不过比较完整的方法是使用拉普拉斯近似。
假设近似的后验概率为高斯分布,中心是真实后验概率的众数。整体上类似于之前的回归分析。不过,没有细看。
神经网络,在引入数学之后变得不再那么仿生学了。但是,现在有很多种各种复杂的网络,在训练中存在一些问题。而使用贝叶斯的方法可以从理论上得到更好的结果,但是在实际过程中通常因为计算复杂,或者根本不可计算求解而陷入问题,因此存在一些近似求解的方法。或者可以用频率学派得到一个相对不错的解。