生成对抗网络(Generative Adversarial Networks)是目前机器学习中比较热的一个方向. 简单的介绍一下GAN的基本原理和阅读最原始的论文.
目录
1 基本原理
考虑一个博弈的场景–制造假币, 警察和犯罪分子的目标分别是什么呢? 对于犯罪分子而言,就是欺骗住警察,让警察分不清真币和假币, 而警察的目标是尽可能的判断出假币. 这就是一个对抗过程, 可以用博弈论理论来建模,这个过程通常称之为对抗过程(Adversarial Process).
Generative Adversarial Nets (GANs)就是特殊的一种对抗过程, 其中警察和犯罪分子都是神经网络, 第一个网络用来生成虚假(fake)的数据, 称之为生成网络G(z)(Generator Net),第二个网络用来判断虚假数据和真实数据,称之为判别网络 D(X)(Discriminator Net),输出结果是0-1,表示这个样本属于真实样本的概率.判别网络采用传统的监督式学习方法进行学习,而生成网络则被训练用于欺骗判别网络.
正式的来说, GANs是结构化概率模型(structured probabilistic model), 包含潜在变了z和观察变量x:
- 判别网络D(x):输入x,真实的样本x, 参数\(\theta^{(D)}\), 希望通过调整\(\theta^{(D)}\)最小化 \(J^{(D)}(\theta^{(D)}, \theta^{(G)})\)
- 生成网络G(z):输入z,随机的输入z, 参数\(\theta^{(G)}\), 希望通过调整\(\theta^{(G)}\)最小化 \(J^{(G)}(\theta^{(D)}, \theta^{(G)})\)
这个对抗过程不同于优化,你无法找到一个全局或者局部最优解, 因为你在优化某一个网络的时候无法控制另一个网络. 这种博弈的解一般称之为纳什均衡, 即一组\((\theta^{(D)},\theta^{(G)})\), 使得在\(\theta^{(D)}\)下,\(J^{(D)}\)局部最小, 在\(\theta^{(G)}\)下,\(J^{(G)}\)局部最小
GANs的优化目标如下V(G, D):
\[\min_G \max_D V(D, G) = E_{x \sim p_d(x)}[\log D(x)] + E_{z \sim p_z{(z)}} [ \log (1 - D(G(z)))]\]简单的来看,我们希望第一项尽可能的大,即真实样本的期望尽可能的大,而第二项尽可能的小,即虚假样本的期望尽可能的小. 对于纳什均衡而言,在不断的博弈过程中,生成网络生成的样本将会逼近真实样本,或者说等价于真实样本, 而判别样本将无法区分出来,得到的概率值都是0.5. 此外,我们可以把这个式子与log_loss = \(y \log p + (1- y) \log(1 - p)\)进行对比.在一个样本下, y要么为1, 要么为0, log_loss本质上只有一项. 而GAN的优化目标是永远都有两个项,即在判别下的y=1, 在生成下的y=0.
从上面的描述, 可以看出GANs的训练是迭代的交替训练,即这一轮训练,先优化一下D(x), 再优化一下G(x). 具体的算法和过程, 在下一个部分介绍.
为什么我们要训练GANs呢?
因为数据的概率分布\(P_d\)也许是一个非常复杂的分布,而且很难解释.GAN 这种竞争的方式不再要求一个假设的数据分布, 有了生成网络之后,可以不考虑\(P_d\)而非常便捷的生成样本, 用于其他的目的等等.
2 算法流程
简单说一下训练的流程:使用batch随机梯度下降的方法训练GANs, k是超参数, 至少是1, 指次迭代中训练D网络的次数. 具体迭代过程如下:
- 循环迭代, 直到达到指定的迭代次数
- 训练迭代k次, 用来训练判别网络D
- 从先验分布\(p_g(z)\)中采样m个随机样本\({z^{(1)}, ... , z^{(m)}}\)
- 从\(p_d(x)\)中随机采样m个样本\({x^{(1)}, ... , x^{(m)}}\), 即从训练样本中随机选择m个样本
- 通过随机梯度下降来训练判别网络D
- \[\Delta_{\theta_d} \frac{1}{m} \sum_{i=1}^m [\log D(x^{(i)}) + \log (1 - D(G(z^{(i)})))]\]
- 结束D的训练, D的网络参数暂时固定, 准备训练G
- 再次 从先验分布\(p_g(z)\)中采样m个随机样本\({z^{(1)}, ... , z^{(m)}}\)
- 通过随机梯度下降来更新生成网络G (仅更新G)
- \[\Delta_{\theta_d} \frac{1}{m} \sum_{i=1}^m [\log (1 - D(G(z^{(i)})))]\]
- 训练迭代k次, 用来训练判别网络D
- 结束
随机梯度下降可以是任意的标准的梯度下降, 比如使用momentum的梯度下降等等.
为什么训练K次D,才训练一次G?
这个主要是因为在有限(或者较少的)数据集上, 判别网络容易过拟合. 所以我们训练k次D, 再训练一次G, 这样的结果是在G不断的缓慢变化时, D仍然在其最优解附近.
此外, 我们从优化目标V(G, D)上看,对于生成网络G而言, 并不能提供很充分的梯度. 具体看, 在训练的初期, G训练不充分,效果并不好, D就可以很容易的判别, 即D(G(z))很小, 那么给生成的loss=\(\log (1 - D(G(z)))\)就会趋近于0, 很难提供梯度给G进行学习. 所以, 在最开始阶段, 可以先用\(\log(D(G(z)))\)来替代\(\log(1 - D(G(z)))\)来训练.
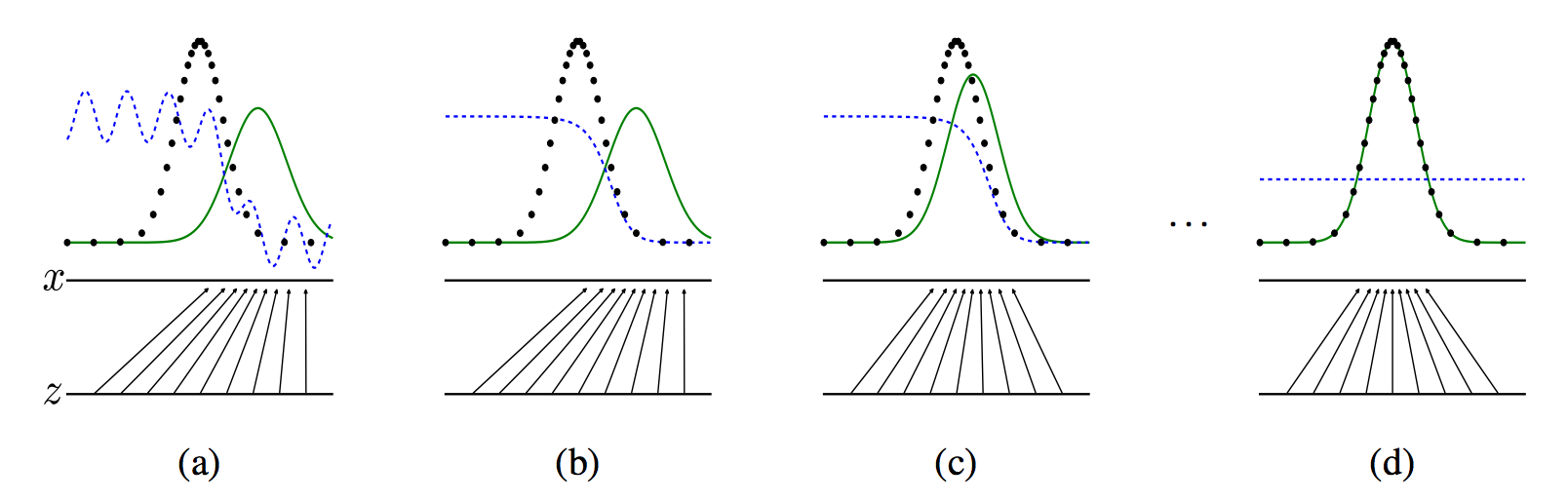
从上图,我们分析一下GANs的训练. 蓝色虚线是我们的判别网络D的结果, 0-1之间表达是否是真实样本, 黑色虚线是真实样本分布\(p_d\), 绿色实现是生成样本分布\(p_g\), x是样本分布, z是先验概率分布, 这个case里是均匀分布, z->x表示了生成网络G根据z生成样本x. 在a图中, 可以认为是训练初期, 某次迭代的收敛, D还不是特别稳定. b图中, D经过k次的训练已经收敛到最优解了 \(D^* = \frac {p_d (x)} {p_d(x) + p_g(x)}\). c图, 在更新G之后, D的梯度会指导G(z)往更可能被判别为真实数据的区域流动. d图是在多次迭代之后, D和G都得到了充分的训练, 就会达到纳什均衡\(p_g=p_d\), 这个时候, D(x) = 0.5
对于b图中的最优, 在第3部分分析.
3 原理分析
上面是介绍了GANs的基本原理, 那么我们想知道这么简单的思路,靠谱吗? 比如说我们用EM算法的时候,是有Jessen不等式或者说ELBO保证收敛的, 那么我们的GANs是一个博弈过程, 道理上能够达到纳什均衡, 但怎么保证的判别回来的结果是在优化生成呢?
首先我们看对于任意生成网络G, D的最优解在什么位置呢? 这个证明很简单,如下:
\[\begin{aligned} V(G, D) &= \int_x p_d(x) \log(D(x)) dx + \int_z p_z(z) \log (1 - D(g(z))) \\ &= \int_x p_{(data)}(x) \log(D(x)) + p_g(x) \log(1 - D(x))d \\ &=> a \log(y) + b \log(1-y) \end{aligned}\]之后一个梯度为0 就可以得到D的最优解 \(D^* _ G(x) = \frac{p_d(x)}{ x}\). 其实D可以看成一个log_loss优化, 那么我们把D的最优解带到V(G, D)中, 可以看到整个式子变为:
\[C(G) = \max_D V(G,D) = E_{x \sim p_d}[\log \frac{p_d(x)}{p_d(x) + p_g(x)}] + E_{x \sim p_g} [\frac{p_g(x)}{p_d(x) + p_g(x)}]\]我们知道对于任意G, D在\(p_g = p_d\)时,达到最优, 这个时候C(G) = -log4, 在上式子中, 我们把分子乘以2, 之后除以2(相当于log的之后减去2), 就会分离出一个\(E_{x \sim p_d} [-\log2] + E_{x \sim p_g} [-\log2]\) = -log4, 那么C(G)可以简写为:
\[\begin{aligned} C(G) &= -\log(4) + KL(p_d || \frac{p_d+p_g}{2}) + KL(p_g || \frac{p_d+p_g}{2}) \\ &= -\log(4) + 2 JSD(p_d || p_g) \end{aligned}\]注: JSD是指jensen-Shannon divergence, 两个分布之间的距离, 避免的KL散度的不对称性
从这个式子可以看出, C(G)的优化会使得\(p_g\)尽可能的接近\(p_d\).
4 pytorch实现
上面介绍了GAN的基本原理之后, 我们可以用pytorch进行实验了!
#!/usr/bin/env python
# coding:utf-8
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
import gzip
import pickle
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import os
class Generator(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Generator, self).__init__()
self.map1 = nn.Linear(input_size, hidden_size)
self.map2 = nn.Linear(hidden_size, hidden_size)
self.map3 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = F.elu(self.map1(x))
x = F.sigmoid(self.map2(x))
return self.map3(x)
class Discriminator(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Discriminator, self).__init__()
self.map1 = nn.Linear(input_size, hidden_size)
self.map2 = nn.Linear(hidden_size, hidden_size)
self.map3 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = F.elu(self.map1(x))
x = F.elu(self.map2(x))
return F.sigmoid(self.map3(x))
class DataGen(object):
"""docstring for DataGen"""
def __init__(self, idx=-1):
super(DataGen, self).__init__()
f = gzip.open("../../../datasets/mnist.pkl.gz", "rb")
(x_train, y_train), (x_test, y_test) = pickle.load(f, encoding="bytes")
f.close()
if idx != -1:
x_train = x_train[y_train == idx]
y_train = y_train[y_train == idx]
self.x_train, self.y_train = x_train, y_train
self.num = x_train.shape[0]
self.idx = 0
self.x_dim = 28 * 28
def next_batch(self, mb_size):
st = self.idx * mb_size
et = (self.idx + 1) * mb_size
if et > self.num:
self.idx = 0
return self.next_batch(mb_size)
else:
self.idx += 1
a = np.array(self.x_train[st:et], dtype="float32")
a = a.reshape(-1, self.x_dim)
x = Variable(torch.from_numpy(a))
return x
def train():
mb_size = 64
z_dim = 100
x_dim = 28 * 28
h_dim = 128
lr = 1e-3
d_steps = 5
top_g_steps = 20000
num_epochs = 1000000
data = DataGen(4)
path = "output4"
# define GAN loss
G = Generator(input_size=z_dim, hidden_size=h_dim, output_size=x_dim)
D = Discriminator(input_size=x_dim, hidden_size=h_dim, output_size=1)
D_solver = optim.Adam(D.parameters(), lr=lr, betas=(0.9, 0.999))
G_solver = optim.Adam(G.parameters(), lr=lr, betas=(0.9, 0.999))
ones_label = Variable(torch.ones(mb_size))
zeros_label = Variable(torch.zeros(mb_size))
c = 0
for epoch in range(num_epochs):
# 优化生成网络
for d_index in range(d_steps):
D.zero_grad()
# 训练真实的样本
x = data.next_batch(mb_size)
z = Variable(torch.randn(mb_size, z_dim))
s = G(z)
D_real = D(x)
D_fake = D(s)
D_loss_real = F.binary_cross_entropy(D_real, ones_label)
D_loss_fake = F.binary_cross_entropy(D_fake, zeros_label)
D_loss = D_loss_real + D_loss_fake
D_loss.backward() # backward只是反馈了, 但是参数仍未更新
D_solver.step() # 进行参数更新
# 优化生成网络
G.zero_grad()
G.zero_grad()
z = Variable(torch.randn(mb_size, z_dim))
s = G(z)
D_fake = D(s)
# 初始化阶段, 对loss少做改变
if epoch < top_g_steps:
G_loss = F.binary_cross_entropy(D_fake, zeros_label)
else:
G_loss = F.binary_cross_entropy(D_fake, ones_label)
G_loss.backward()
G_solver.step()
# Print and plot every now and then
if epoch % 1000 == 0:
loss_d = D_loss.data.numpy()
loss_g = G_loss.data.numpy()
print('iter={}, D_loss={}, G_loss={}'.format(epoch, loss_d, loss_g))
# 随机取生成的前16张进行可视化
samples = G(z).data.numpy()[:16]
fig = plt.figure(figsize=(4, 4))
gs = gridspec.GridSpec(4, 4)
gs.update(wspace=0.05, hspace=0.05)
for i, sample in enumerate(samples):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(sample.reshape(28, 28), cmap='Greys_r')
if not os.path.exists(path):
os.makedirs(path)
plt.savefig('{}/{}.png'.format(path, str(c).zfill(3)),
bbox_inches='tight')
c += 1
plt.close(fig)
if __name__ == '__main__':
train()
跑了几组实验, 感觉效果很一般. 代码是参考了网上50行代码的实现.
5 问题与参考
参考论文 Generative Adversarial Nets 在文章的最后, 也提出了一些GAN存在的一些问题, 以及和其他生成模型的对比. 当然, 这个是最basic的GAN了, 后续还有很多的改进, 尤其是WCGAN的出现.