谷歌的GooglePlay的推荐模型Wide and Deep Learning 模型,目前已经提供了tensorflow的开源版本。
目录
之前做了简单的笔记,分享一下。其中,有好多词语,翻译成中文就感觉表达的意思少了点,不够完善了。所以,这篇文章里,很多词语还是保持了一些英文,但是首次出现的时候都用了部分中文解释下了。
谷歌论文博客地址:Google_Wide&Deep Learning.pdf
摘要
非线性特征变换和广义线性模型结合被广泛的应用于大规模稀疏输入的回归和分类问题。记忆(Memoization,后面会解释)不同特征之间的交互组合(interactions)是非常有效且有很好的可解释性,但是较好的泛化能力要求大量的特征工程。
而深度学习可以通过学习稀疏特征的embedding(简单的可以理解为,用一个向量来表达一个具体的特征)来达到更好的泛化能力(泛化到一些没有见过的特征组合上)。但是深度学习会过泛化(over-generalize),即在use-item的interactions比较稀疏和高排名(high-rank)的情况下,会推荐一些不太相关的东西。
这篇文章就是将现行模型和深度神经网络结合起来用于推荐,能够获得memoization和generalization收益。
介绍
为了方便解释,我们以给用户推荐app为例, 推荐系统可以被看做是一个搜索排序系统(search ranking system),输入是用户的信息和app信息,而输出是对于每个用户的排好序的app列表。对于一个给定的query(查询),推荐系统的目标是在数据中找到相关的item,然后基于一定的目标(比如点击或购买等)进行item的排序。 推荐系统的一个挑战,类似于搜索排序系统,是如何同时满足memorization 和 generalization。memorization可以解释为学习到items或者features的共现(co-occurrence)关系,并利用好历史数据里的相关性。而generalization就是在新的数据上有较好的表现。基于memorization的推荐系统,通常更加偏向用户关注的,或者与用户历史的展现动作非常相关的。而generalization更倾向于提高推荐内容的多样性! 谷歌这篇文章是用于app推荐的,会更加的倾向于而generalization。
工业界经常使用logistic 回归模型来做大规模在线推荐和排序系统(可以参看之前的文章FTRL)。首先特征都是binary的,比如用户安装了netflix,那该特征就是1,否则就是0。这里举了一个例子,来解释memorization,类似于“与”操作,比如用户安装netflix同时浏览了pandora,这个特征是1,否则就是0,所以这种共现通常需要手动设计。这种特征组合对于没有出现在训练数据中的组合都不具有泛化性。
Embedding的模型,比如FM(factorization machines,见之前的博客)或者深度神经网络,可以通过学习到query和item的低维的向量来达到之前没有见过的一些特征组合,而且不需要太多的特征工程。然而在query和item矩阵sparse 和 high-rank的情况下(比如query比较特别或者item比较有偏,导致二者之间没有interaction),很难学习到有效的低维表达,导致推荐一些不太相关的item。但是这种情况下,embedding的结果是非零向量,一定会over-generalize,推荐一些不相关的。而使用特征组合的线性模型的时候,就能学到这种“exception rules”了。
谷歌使用的方法如下图所示:
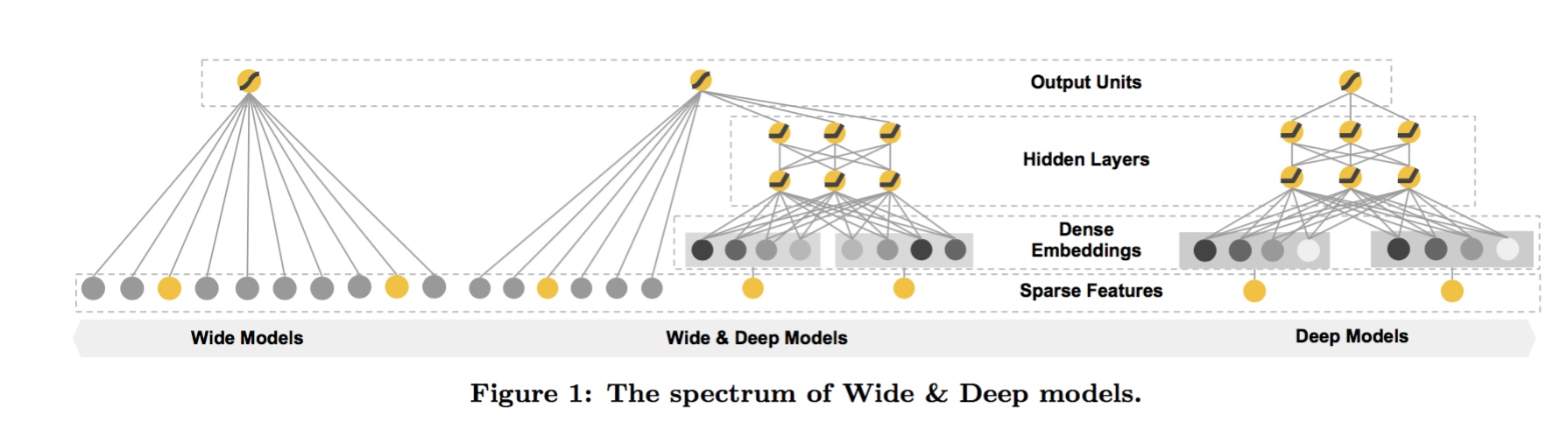
主要贡献如下:
- embedding和线性模型的组合训练
- 在Google Play上实现和评估了,十亿用户和一百万apps
- 在tensorflow上开放了API
虽然想法比较简单,但是谷歌做到了训练和服务的快速响应。
论文详细
推荐系统概述
下图概述了一下推荐系统
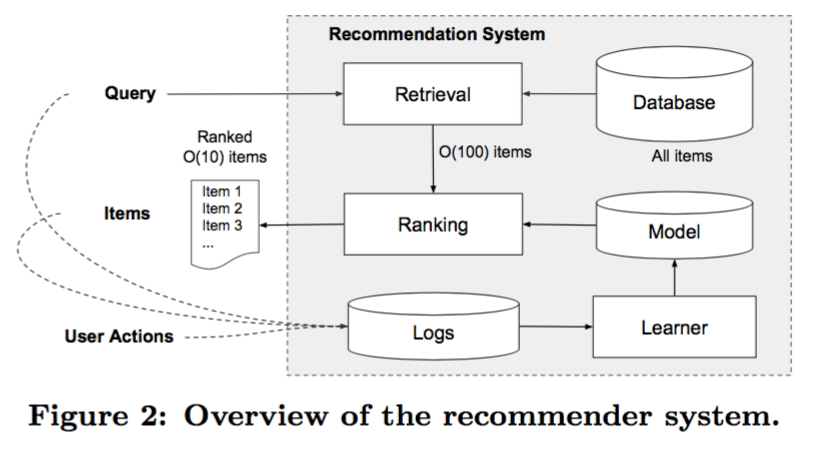 这里主要提到一点是数据库有一百万的app,直接取出来推荐压力太大,所以会有一个检索系统,就是从数据库基于机器学习模型和一些人工规则筛选出一部分app列表,之后才是排序,预估分数P(y|x),x是一堆特征,包括用户的特征比如国家语言等、环境相关(contextual)特征比如设备,星期等,还有展示特征比如一个app的历史统计等。这篇文章主要关注排序模型。
这里主要提到一点是数据库有一百万的app,直接取出来推荐压力太大,所以会有一个检索系统,就是从数据库基于机器学习模型和一些人工规则筛选出一部分app列表,之后才是排序,预估分数P(y|x),x是一堆特征,包括用户的特征比如国家语言等、环境相关(contextual)特征比如设备,星期等,还有展示特征比如一个app的历史统计等。这篇文章主要关注排序模型。
WIDE & DEEP LEARNING
Wide就是线性模型,包含一些组合特征,注意特征都经过类似于one-hot encodding处理成0-1的binary特征。deep 的那部分是一个神经网络,输入是特征类似于“language=en”,这些稀疏的,高维度的categorical特征,首先会转化成一个低维度实数向量,即一个embedding vector,一般维度选择可以从10 到100,随机初始化这些vector之后,通过最小化最终的loss进行学习。这些vector输入到神经网络中并前向传递到最后。
最终两个数值是通过加权求和之后再logistic变化得到预测值(即两个数值输入到一个logistic回归里)。 joint training和ensemble不同的地方就是ensemble是单独的训练各个模型, 而joint training是在训练过程同时训练多个模型 另外,ensemble因为是独立的所以各个模型需要非常大(因为特征和特征组合比较多),而joint training中的deep部分只需要部分wide部分的特征而已。在实际求解中,使用了FTRL+L1来优化wide部分,使用AdaGrad来优化deep部分。
系统实现
主要包括三个部分,如下图所示:数据生成(data generation),模型训练(model training), 和模型服务(model serving)
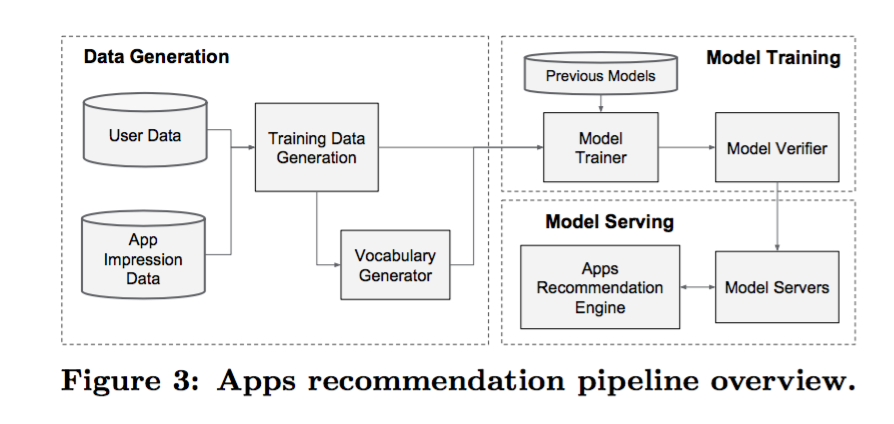
- 数据生成:用户浏览的app,如果安装了1,否则就是0.一些基本的特征处理,也在这里做了,比如将app映射到id,将实数特征离散化到0-1.
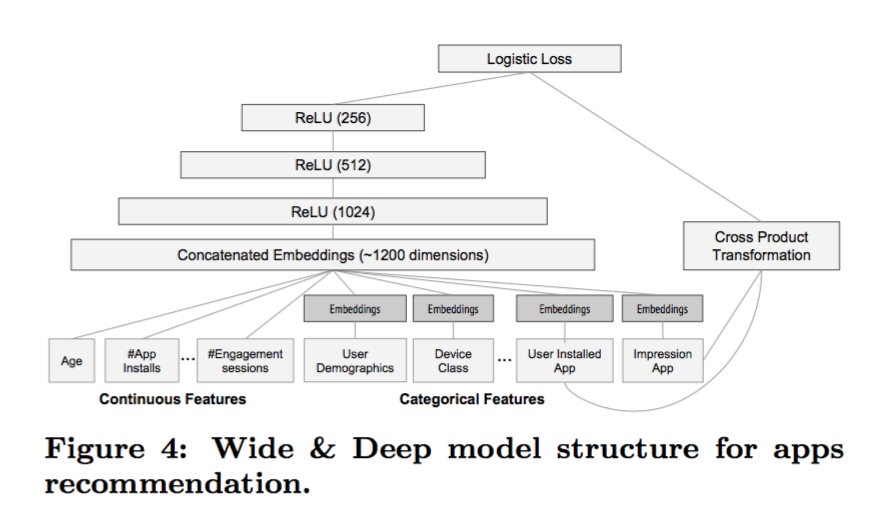
- 模型训练:详细的模型如下图所示。wide部分是包括用户安装的app和浏览过的app特征组合,而deep部分 使用了32维的向量来表达各个categorical特征,之后组合得到了1200维向量,在使用3个ReLU layer降维到256,最后使用logistic回归。模型使用了5000亿样本,每次新来了一组训练数据,模型都要被重新训练,但是都是在上一个模型基础上训练(可以看作是online training吧)。模型上线之前还会和之前的模型做个对比,保证安全
- 模型服务:模型训练并且验证完了之后,就放到model servers上。每次请求来了,都会从数据库中获取一堆app并获取用户的特征,之后用模型进行排序。为了快速响应,使用分布式的预估。
实验结果
主要评估了app的安装率(App Acquisitions)和服务性能(Serving Performance)。简单的说就是app获取方面有提升,check了在线和离线的AUC,同时也发现embedding部分能够产生一些探索推荐。服务方面有挑战,但还是好快好快的。
相关工作与总结
语言模型里,将RNN和传统的最大熵模型(n-gram的输入)进行组合来减小RNN的复杂度。图像里的残差网络,也算一个类似的。 memorization and generalization是推荐系统比较重要的两个方面,谷歌的这个方面在online实验里是明显提升了app 安装率。