FM 模型用于推荐,提供了在非常大特征空间且非常稀疏的情况下更好得学习参数的一种方法。
目录
介绍
FM模型作为一个预测模型,和SVM一样能够用于各种预测问题,但是他同时考虑变量之间的交互关系。另外,本文也讨论了在协同过滤的场景下,为什么SVM、一些如PARAFAC的矩阵分解模型、因子参数等等模型效果不好呢?归根结底是因为这些模型(SVM)在复杂(非线性)核空间以及非常稀疏的情况下,无法学习到可靠的参数。而其他的一些矩阵分解和特定得模型,通用性不太好。 FM的主要优点:
- FM可以在非常稀疏的数据中很好的进行参数估计,而SVM不行
- FM是线性复杂度,而且不像SVM那样依赖于样例(支持向量)
- FM可以用于离散的或者连续的数据,而很多模型对输入有要求。
稀疏性
对于推荐来说,比如电影推荐,把电影评分由一个评分矩阵展开成训练样本。评分矩阵本身就非常的稀疏,展开之后如下所示,前面4列是用户id,后面跟着5列的是电影的id,再后面的5列是一些相对含蓄的指标,比如归一化的评分占比,后面一列是时间,再后面几列是上一次评分的电影,最后是评分的值。
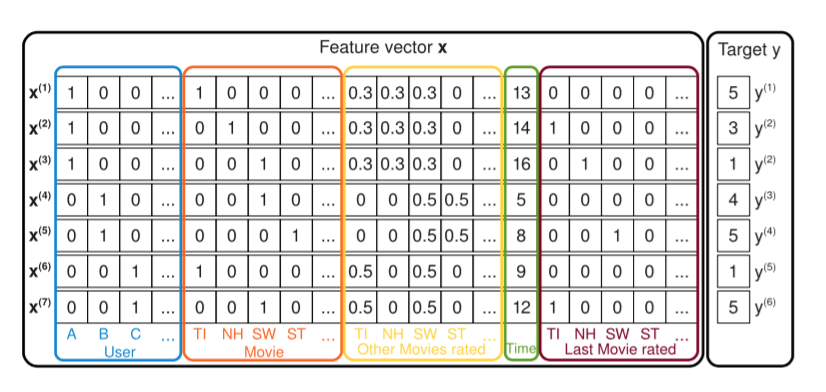
这个训练样本是非常稀疏的,尤其是当电影比较多,每个用户可能只看了其中很小的一部分。
FM模型介绍
Factorization Machine 模型
1、下面给出一个degree d=2情况下得FM模型等式:
\[\hat{y}(x) := w_0 + \sum_{i=1}^n w_i x_i + \sum_{i=1}^n \sum_{j=i+1}^n < v_i, v_j > x_i x_j \ \ 公式(1)\]公式1的参数\(w_0 \in R, W \in R^n, V \in R^{n * k}\),其中<>表示点乘,即\(< v_i, v_j > := \sum_{f=1}^k v_{i,f} * v_{j,f}\)。简单的来说,对于每一个维度的特征,都会对应一个v(因子向量,向量维度是k),而 \(\hat{w}_{i,j} = < v_i, v_j >\) 表达了变量i和变量j之间的交叉关系,而不是采用一个参数 \(w_{i,j} \in R\)来表达这些交叉关系。后面会看到这是在稀疏数据且特征多重交互(d > 2)情况下,能够保持较好得参数估计的关键
2、对于正定矩阵W一定可以分解为\(V*V^T\),只要k足够大。但是为了更好的估计这些交叉特征的权重,一般会选择一个较小的k。通过控制k,来达到更好的泛化能力。
3、稀疏情况下的参数估计:在稀疏的情况下,直接和独立的估计交叉特征的权重,很难有这么多数据,因为独立更新权重的时候,因为输入的稀疏导致权重梯度为0,而无法有效的更新权重。而FM模型因通过分解而打破了这种的独立性,也就是说对于一种交叉特征的更新会帮助其他的交叉特征。举例说,对于图一里的电影投票数据,特征A和特征ST做一个交叉特征来预测y,因为训练数据中没有此类样本(A,ST不同时为0的样本),因此学习到得权重\(w_{A,ST}=0\)。但是如果分解了的话\(< v_A,v_{ST} >\),就可以进行估计了。在样本中,B、C都看过SW,那么\(< v_B, v_{SW}>\)和\(< v_C, v_{SW}>\)结果类似,而B看过的两部的电影,那么他们分解出来的向量也会比较相似,而把这些结果再应用到其他样本上时,就会产生一些相似结果,直观的理解就是从别得地方学习的东西用于当前学习。
4、证明了时间复杂度是O(kn),因为两两特征的交叉乘积(想象一下交叉乘积的方阵之后求和)可以转化为整体的平方减去对角线上的平方值之后的一半。如下:
\[\sum_{i=1}^n\sum_{j=i+1}^n < v_i, v_j> x_i x_j = \frac{1}{2}\sum_{f=1}^k ((\sum_{i=1}^n v_{i,f}x_i)^2 - \sum_{i=1}^n v_{i,f}^2 x_i^2)\]另外,FM可以用于回归、分类、排序!在这些场景中,都可以使用L2正则来避免过拟合。
FM模型学习
用随机梯度下降(SGD, stochastic gradient descent)学习,对于FM如下,y对于各个参数的偏导数如下:
- 对于\(w_0\),梯度是 1
- 对于\(w_i\), 梯度是 \(x_i\)
- 对于\(w_{i,j}\), 梯度是 \(x_i\sum_{j=1}^n v_{j,f} - v_{i,f}x_i^2\)
那么问题来了。如果在神经网络中嵌入FM的话,还需要考虑什么?考虑把误差反馈的情况,那么误差反馈的公式呢?对于\(x_i\)的梯度是\(w_i + \sum_{f=1}^k(v_{i,f}x_i - v_{i,f}^2)\)
总结一下,使用FM的两大优点:
- 在高度稀疏下,仍然能够学习到交叉特征权重
- 参数以及学习和预测的时间都是线性的,SGD就可以求解
模型比对
对于普通的SVM,那么类似于FM中的d=1,也就类似于普通得logistic回归。对于polynomial 核的SVM,其实是类似做了特征变化之后(增加平方或者高次项)的LR,再加上一些特征交叉项。本质上,求解过程中特征交叉项得到的新特征与其他特征相互独立,求解是相互独立的,导致很难在稀疏下学习到参数值。 简单的来说,FM中交叉特征的权重,比如用户\(v_A\),可以不在ST特征的交叉中学习,但是可以在其他的特征交叉下学习到。 对比SVD等等矩阵分解模型,更容易添加一些特征,比如用户相关或者电影相关得特征,而不用针对评分矩阵进行分解。