之前工作里写过CNN,一眨眼,快到一年了。写CNN的过程,使我有了很大的成长,对BP的理解也深刻了许多。之前写得文档里,只是针对论文做了一个解析,现在放出一些关键的推导过程,也稍微回顾一下。关于训练模型里的一些trick,很多时候是需要尝试的,我突然发现:其实也很需要想象力!
注:很多图片是之前做的PPT截图,如果用mathjex重复打公式和排版了,比较费时间,所以直接截图了。
目录
1、卷积神经网络
卷积神经网络(convolutional neural network)是利用模型特性来处理掉输入的波动而获得不变性特征,由LeCun提出,目前广泛的应用于图像数据。
2、基本操作
卷积操作主要是f(x)g(x)在重合区域的积分。
-
一维卷积 如下图所示,是一维卷积。类似于点积,\(y = x*w\),下图的w=[1,0,-1]。这里引入了一个概念局部接受野(local receptive fields)和权值共享(weight sharing)。为了方便表述,灰色的是隐含层i,黄色是下一层隐含层i+1。对于传统的神经网络而言,i+1层的一个神经元是接收了i层所有神经元节点的加权求和得到的,而这里,则仅接收i层神经元局部输入的加权得到,也就是局部接受野的概念。而权值共享,指的是对于i+1层的每一个神经元用的权重w是同一个。原来是7个输入5个输出的话,那么需要w是75=35个参数,如果使用局部接受野,输入变为了3,则需要w是35=15个参数。如果再使用权值共享,那么就变成了3个参数!使得整个网络的参数大为减少。
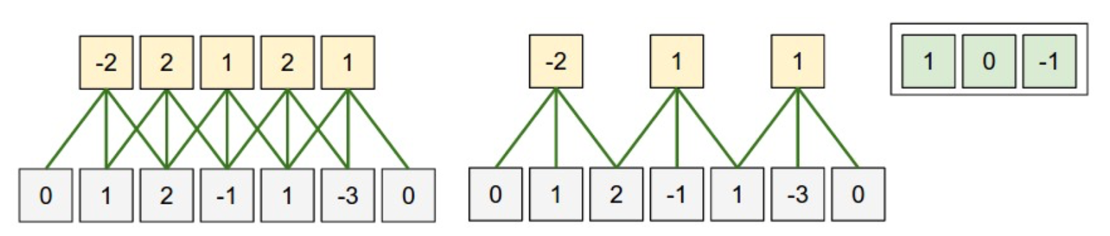 当然,i层可以对应多个i+1层,也就是每一个共享的w得到一个i+1层,多个共享的w就得到了多个i+1层,这个数一般称之为feature map数。这样可以学习到更多的特征。
这样能够更好的表达局部特征!而通过不断的深度,使得局部特征聚合为高级特征
当然,i层可以对应多个i+1层,也就是每一个共享的w得到一个i+1层,多个共享的w就得到了多个i+1层,这个数一般称之为feature map数。这样可以学习到更多的特征。
这样能够更好的表达局部特征!而通过不断的深度,使得局部特征聚合为高级特征 - 二维卷积
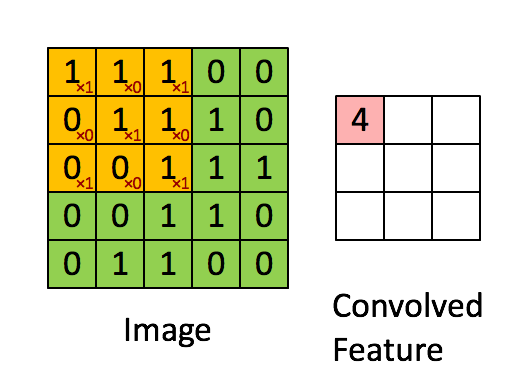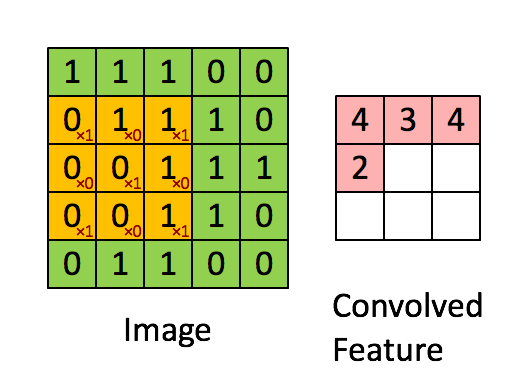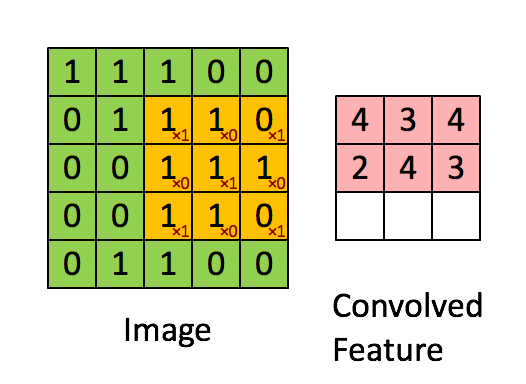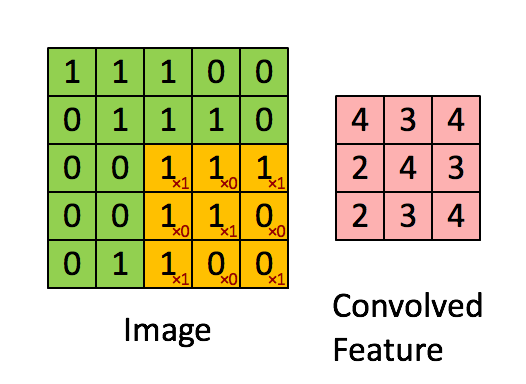 这里不细说,下面会细说。
这里不细说,下面会细说。 - 三维卷积
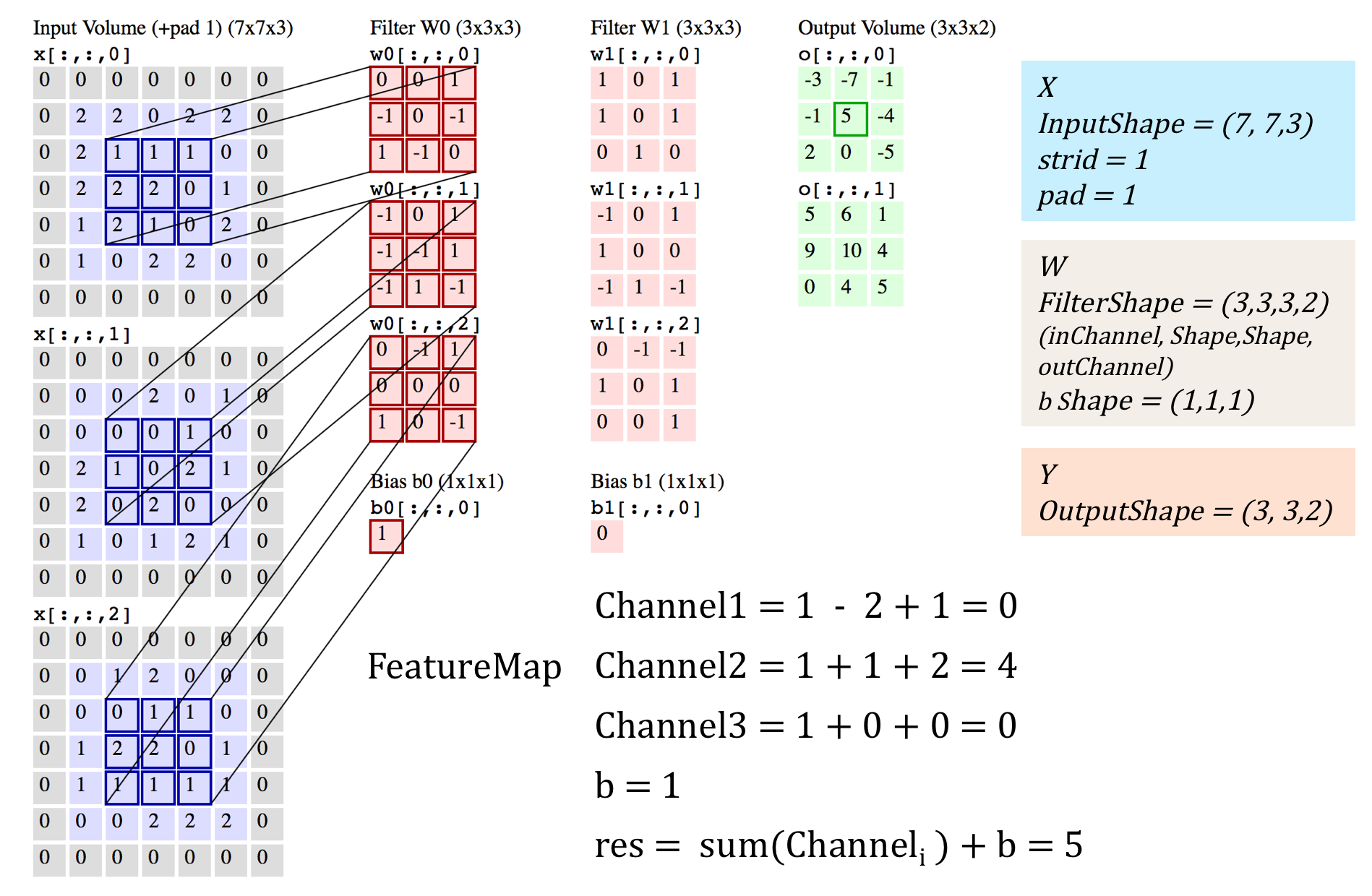 目前多数都是采用3d卷积,本质跟2d卷积一样。就是维度增加了,对应的输入变为了4维,而w也是4维的,这样卷积求和得到输出。
目前多数都是采用3d卷积,本质跟2d卷积一样。就是维度增加了,对应的输入变为了4维,而w也是4维的,这样卷积求和得到输出。
除了卷积之外,cnn还有一个核心的概念,子抽样(subsampling),一般用pooling来表示。pooling的种类有很多种,主要是用一个特征来表达一个局部特征,这样使得参数大为减少。常见的有max pooling和mean pooling,L2 pooling。max pooling就是用局部特征的最大值来表达这个区域的特征。其他依次类推。如下图所示:
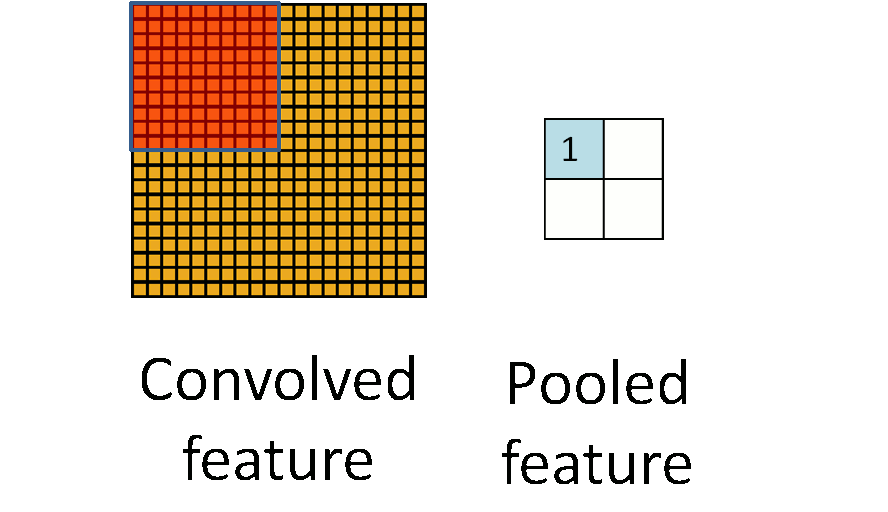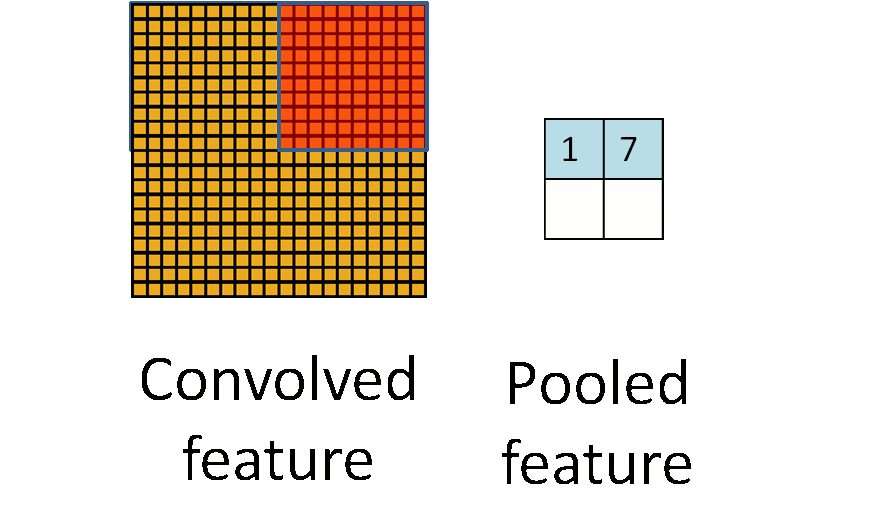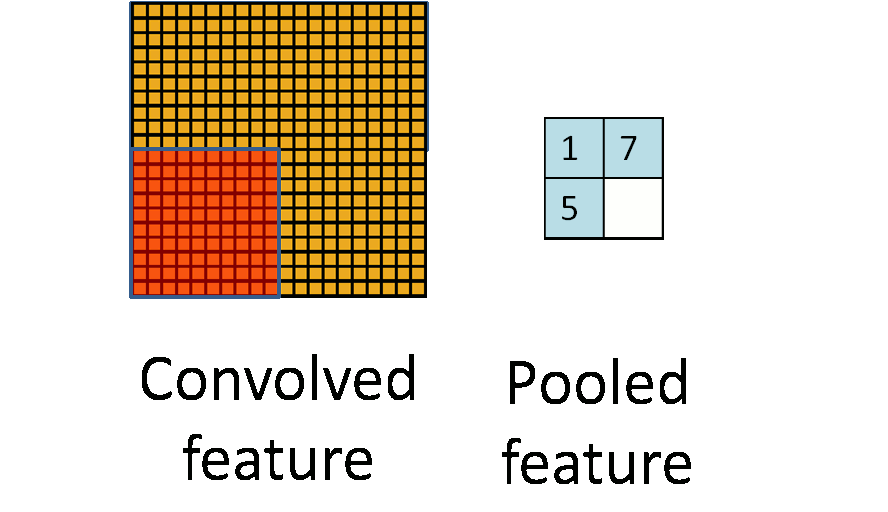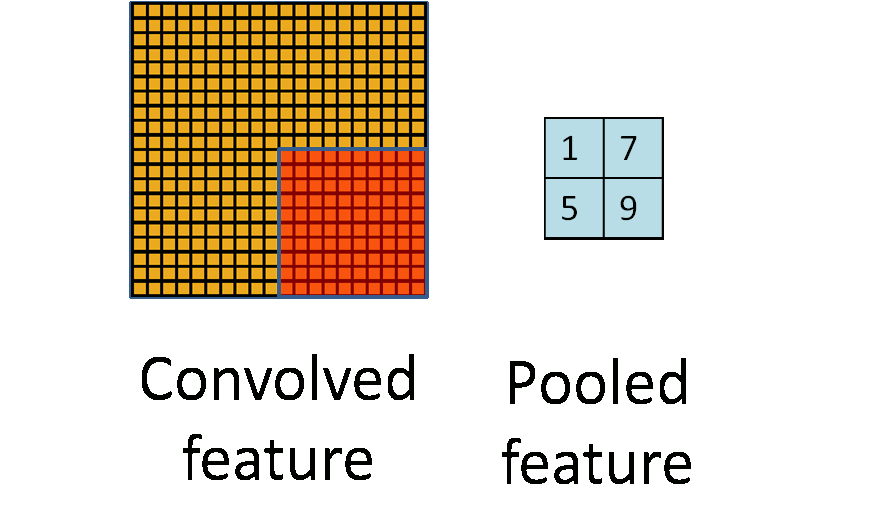
另外,对于图像里的一些其他操作,比如stride,表示卷积每次的移动步长,pad表示对图像进行阔边,防止在卷积操作中丢失边界特征。
3、卷积的BP
卷积的BP推导可以概括为3个卷积。具体如下:
这里我们以2d卷积为例子,3d卷积的话,就是在2d上增加一个循环就可以了。
如下图所示:
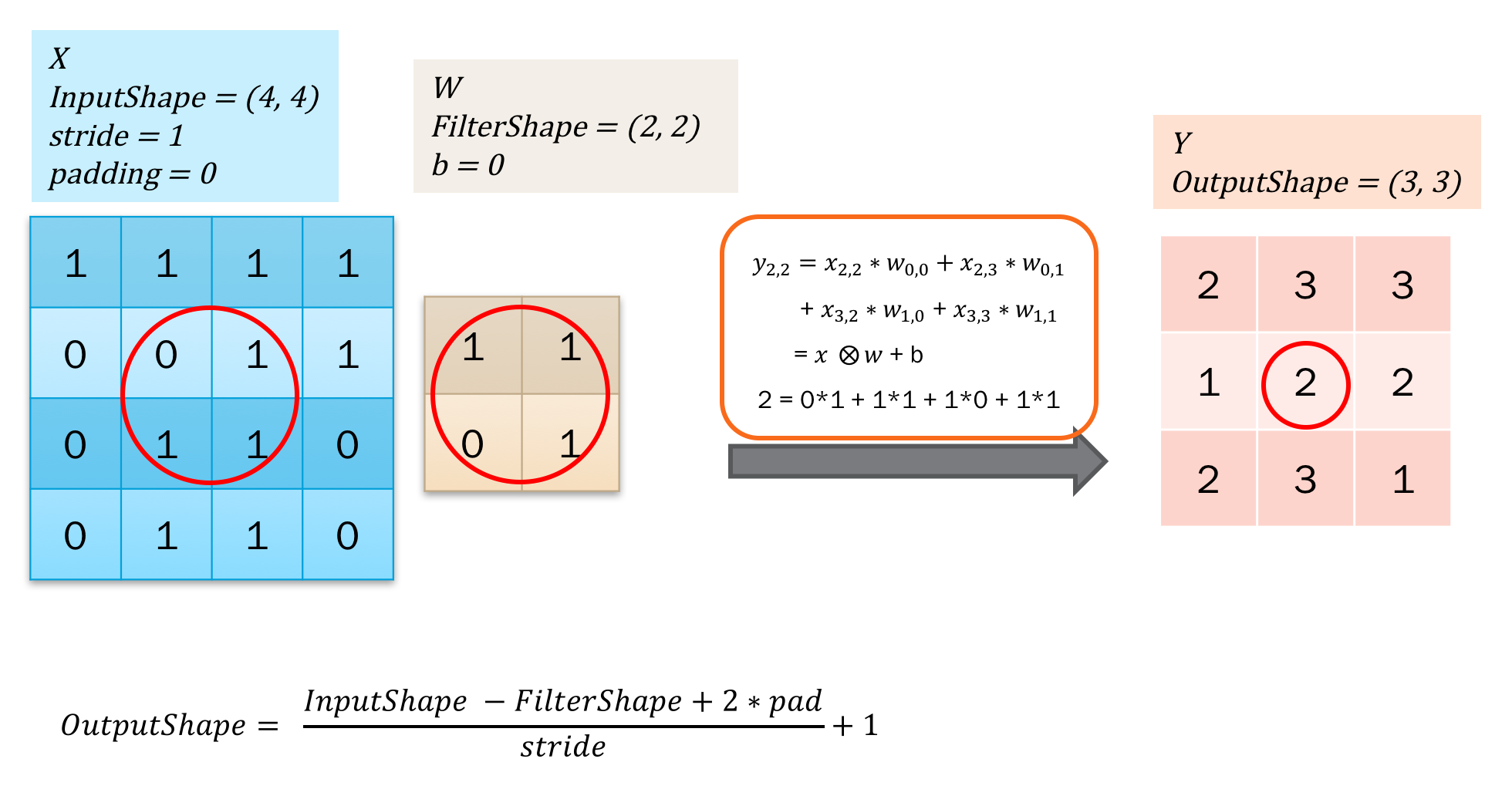
这是一个forward过程,就是第二部分提到的卷积操作。这里仅用大O里面加个x表示卷积,注意后者是卷积核,也就是filter或者说weight。
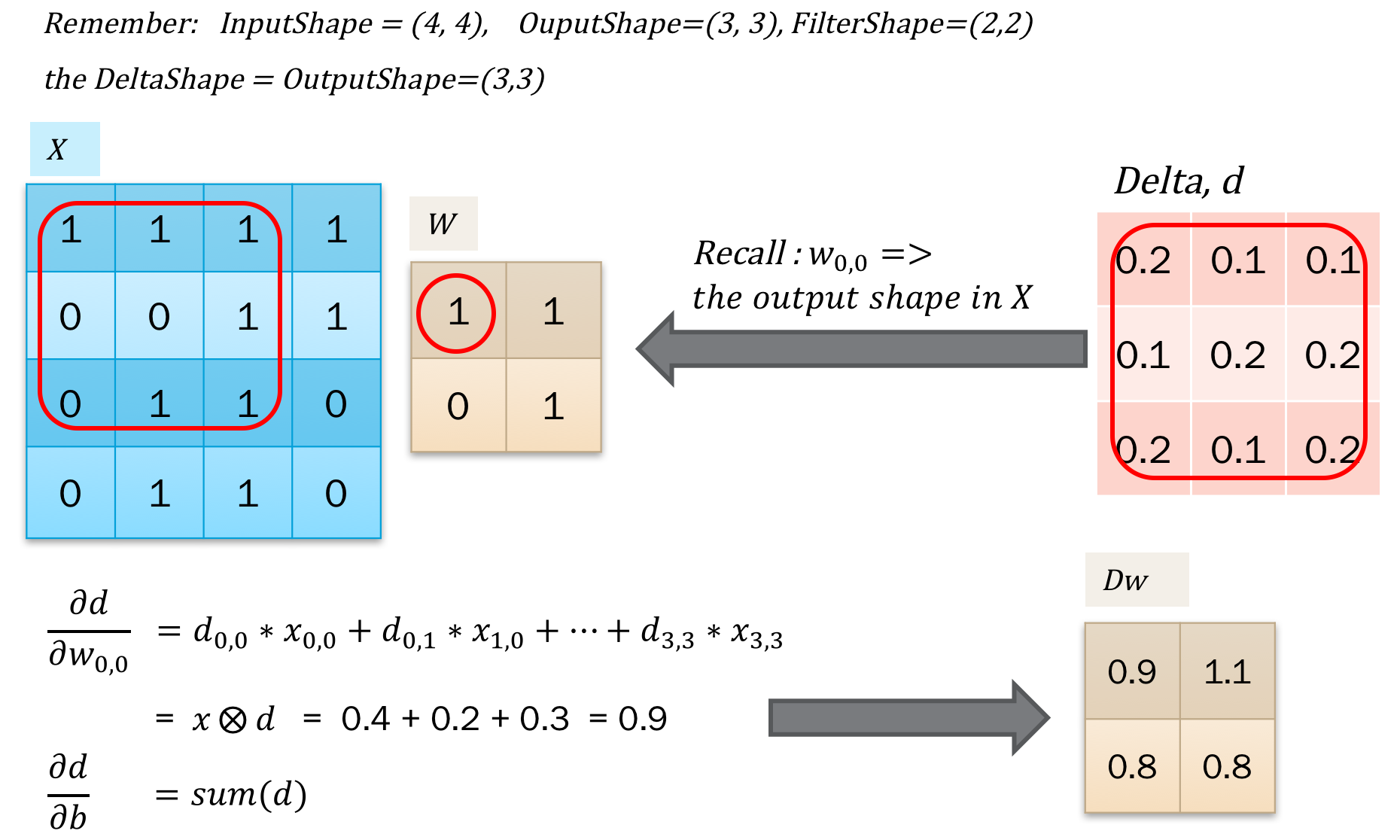
那么误差反馈就比较容易,首先是得到了上层传递过来的delta,之后对输入的x求导得到dx用于反馈误差。之后对w求导,得到dw,用于更新梯度。
这个比较简单,因为本质都是点积,只需要对应的求导再加和就可以了。如下图所示:
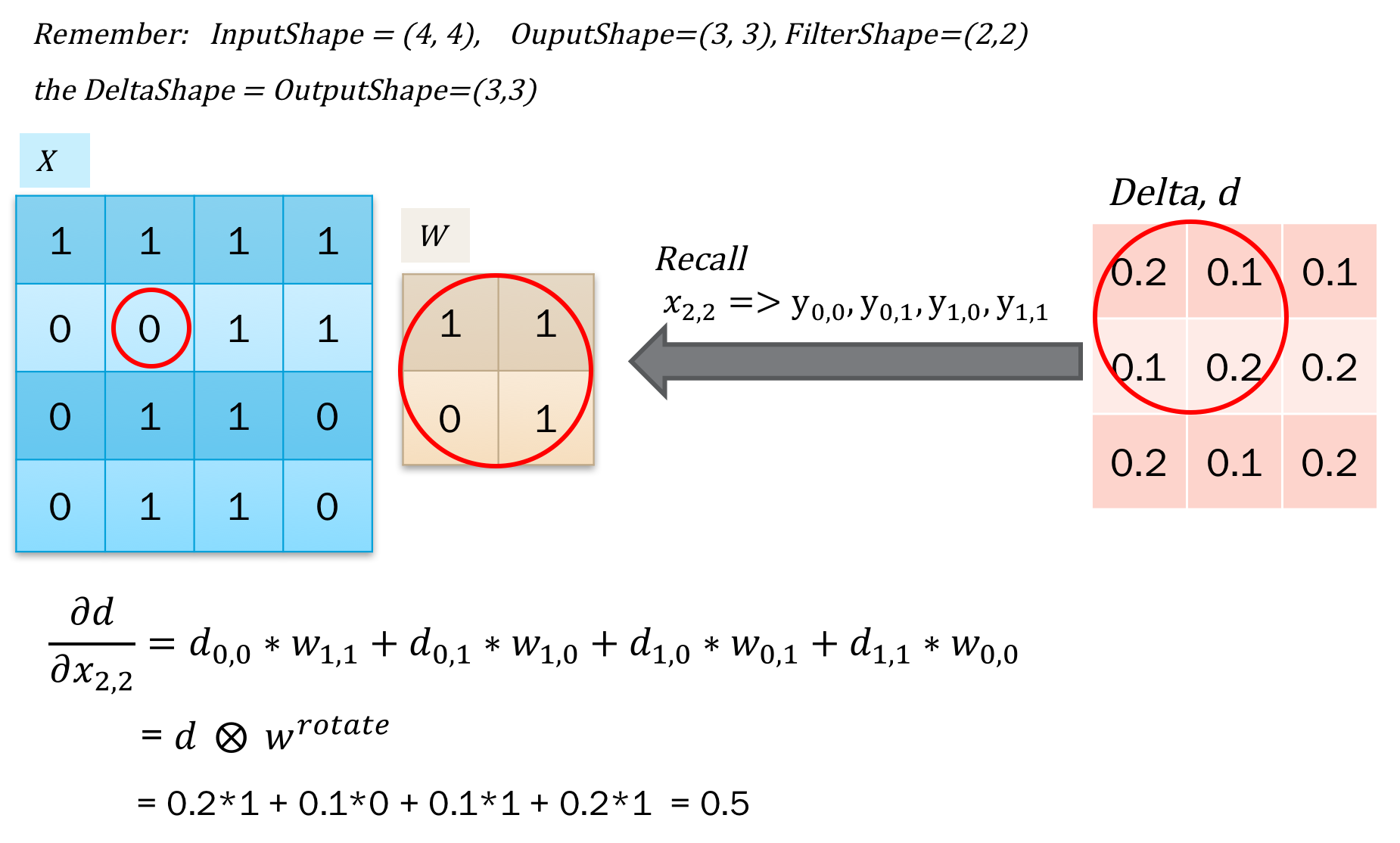 对应的求解,发现这个操作类似于卷积。但是对于\(x_{0,0}\)的求解,需要对delta进行阔边以方便直接使用卷积操作。如下图所示:
对应的求解,发现这个操作类似于卷积。但是对于\(x_{0,0}\)的求解,需要对delta进行阔边以方便直接使用卷积操作。如下图所示:
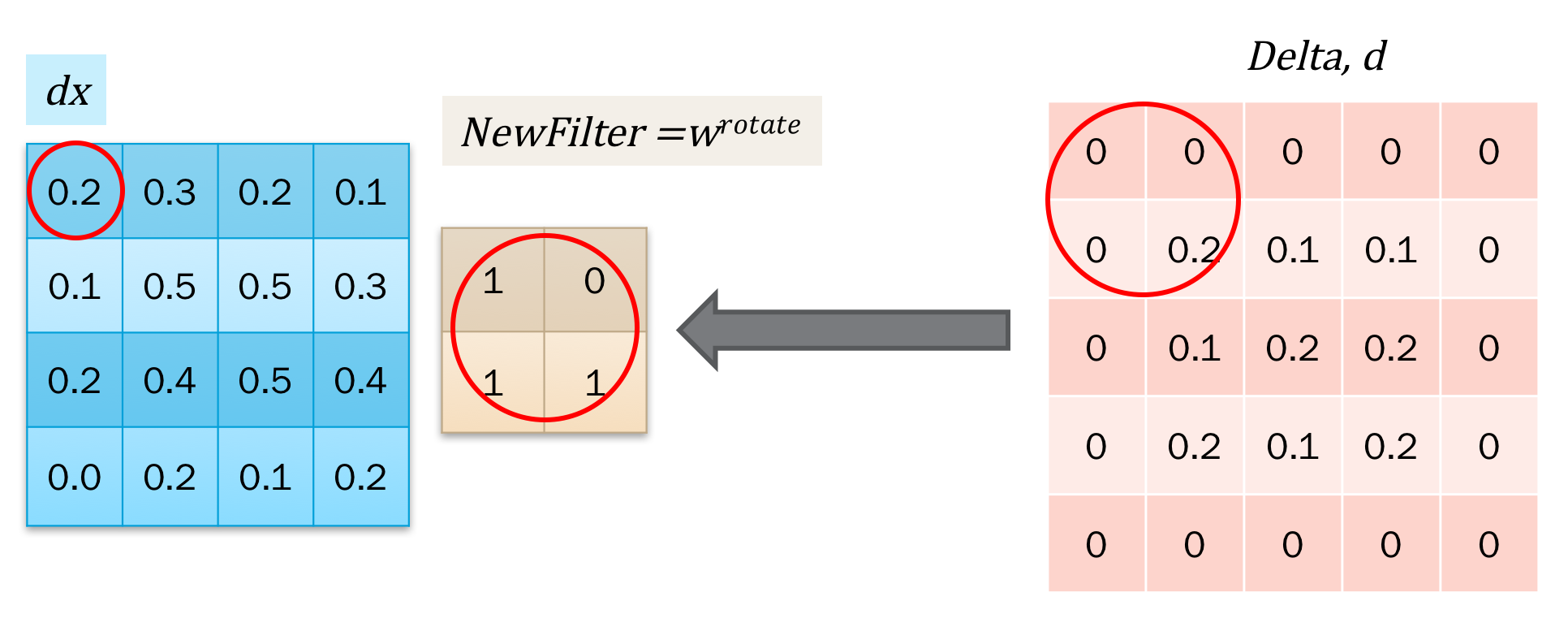
接下来是对w求导,得到更新梯度。计算也是一样的,找到w参与的点积计算,拿到导数合并一下就可以了。如下图所示,我们发现同样可以用卷积操作来表示:
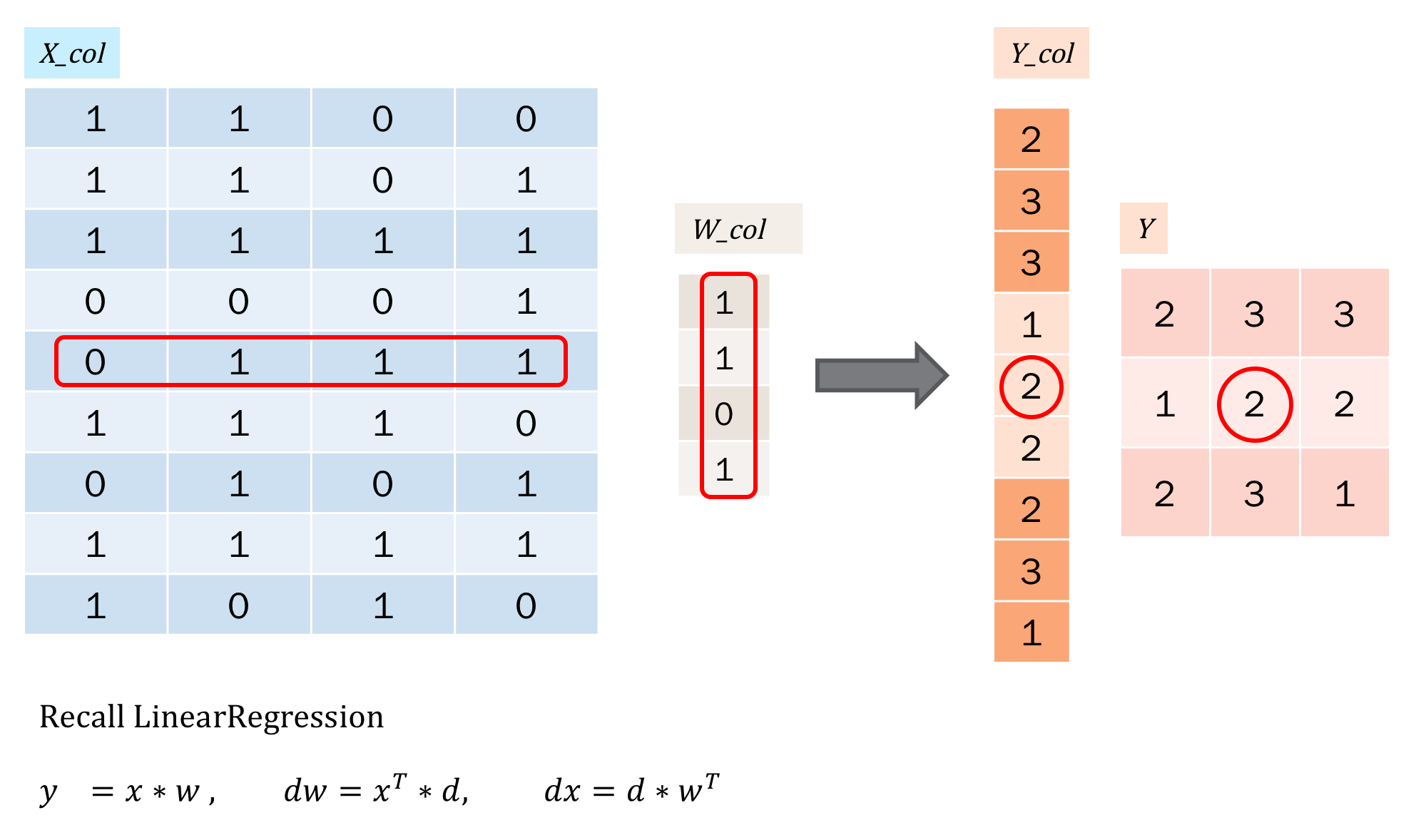
那么我们可以联系到线性回归,以方便我们记忆了:
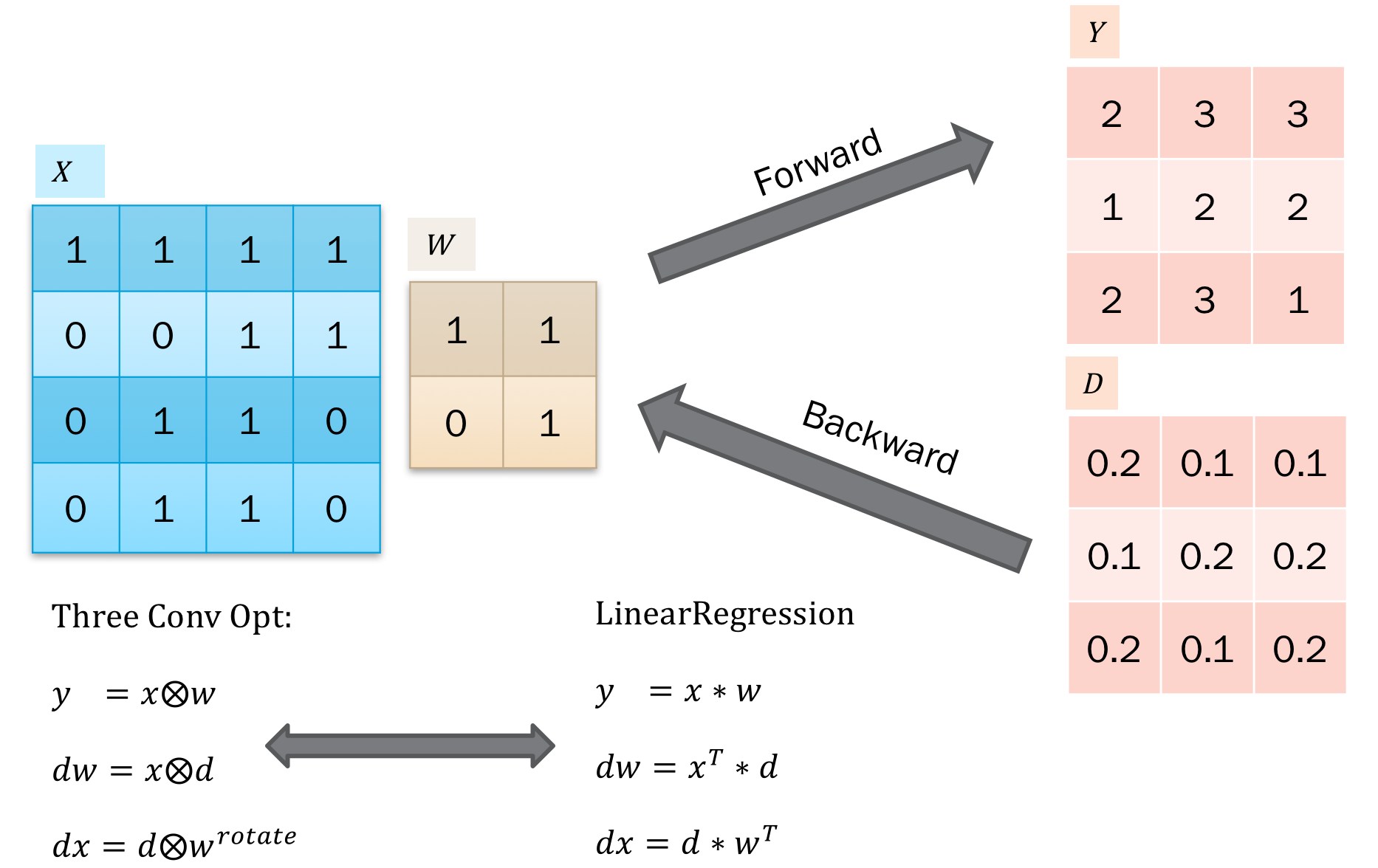
以上就是关于卷积BP的推导和证明了。图片是在ppt里编辑好之后截图过来的,因为直接写一堆公式的话,感觉容易乱。 此外,我们看到也能看到对于55的卷积操作,其实是可以用2个33的卷积操作来代替,同时还能达到层数更多的效果。目前通过可视化来看,深度学习的特征是层级式的,特征由低级不断的汇总为高级特征。
4、pooling层BP
对于pooling层,如何进行BP操作呢?pooling层比卷积层简单的地方是,pooling是没有参数的,所以只需要得到dx之后用于误差传递就可以了。对于mean pooling,其实相当于卷积都是均值,比如2*2的pooling,那么w就相当于[[0.25, 0.25],[0.25, 0.25]],我们直接套用卷积的公式就可以了。而对于L2 pooling等等类似的pooling,其实是可以拆分成平方操作,sum pooling,再开方的三个操作分别传递误差就可以,而sum pooling也可以套用卷积操作。唯一不一样的是max pooling,没有固定的卷积核,所以需要循环一下,对于输入最大的点进行求导。pooling 如下图所示:
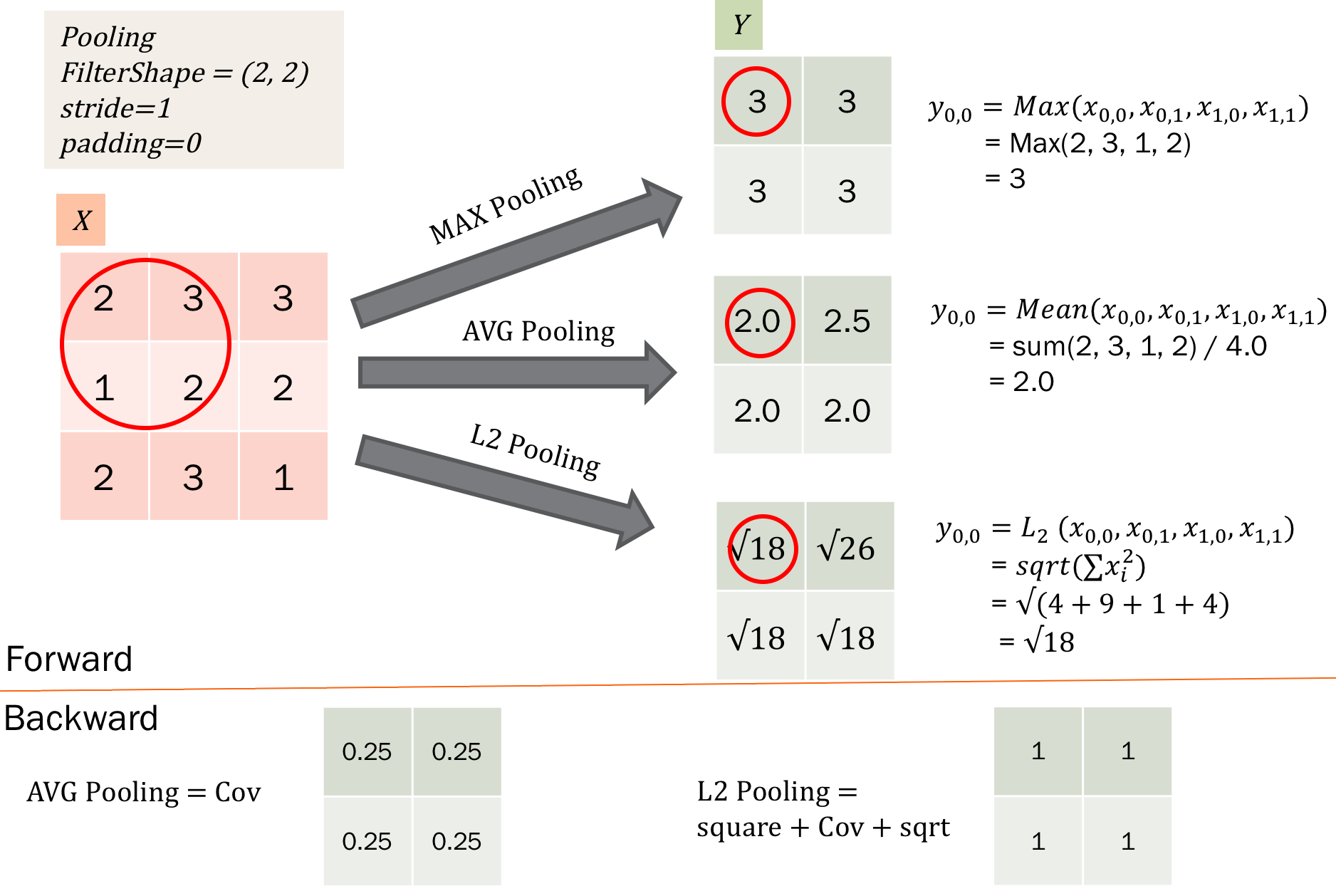
从max 和 mean等操作也可以看到,pooling的不同。 pooling的本质是一种局部特征的表达。max pooling的是用图像某一区域像素值的最大值来表示该区域的特征,而mean pool是用图像某一区域像素值的均值来表示该区域的特征。这两个pooling操作都提高了提取特征的不变性,而特征提取的误差主要来自两个方面:
- 邻域大小受限造成的估计值方差增大;
- 卷积层参数误差造成估计均值的偏移。
一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差(导数不影响其他点),更多的保留纹理信息。在图像处理中,使用max pooling多于mean pooling。
5、im2col
实际在计算的卷积的时候,通常可以使用一些卷积操作库。在类比线性回归的时候,也容易想到,如果把二维的卷积核w转为一维的话,操作会不会更快?因为在误差反馈的时候,不需要再重复的循环。因此,有一种方式是把二维图像转为一维向量进行计算的方式。如下图所示:
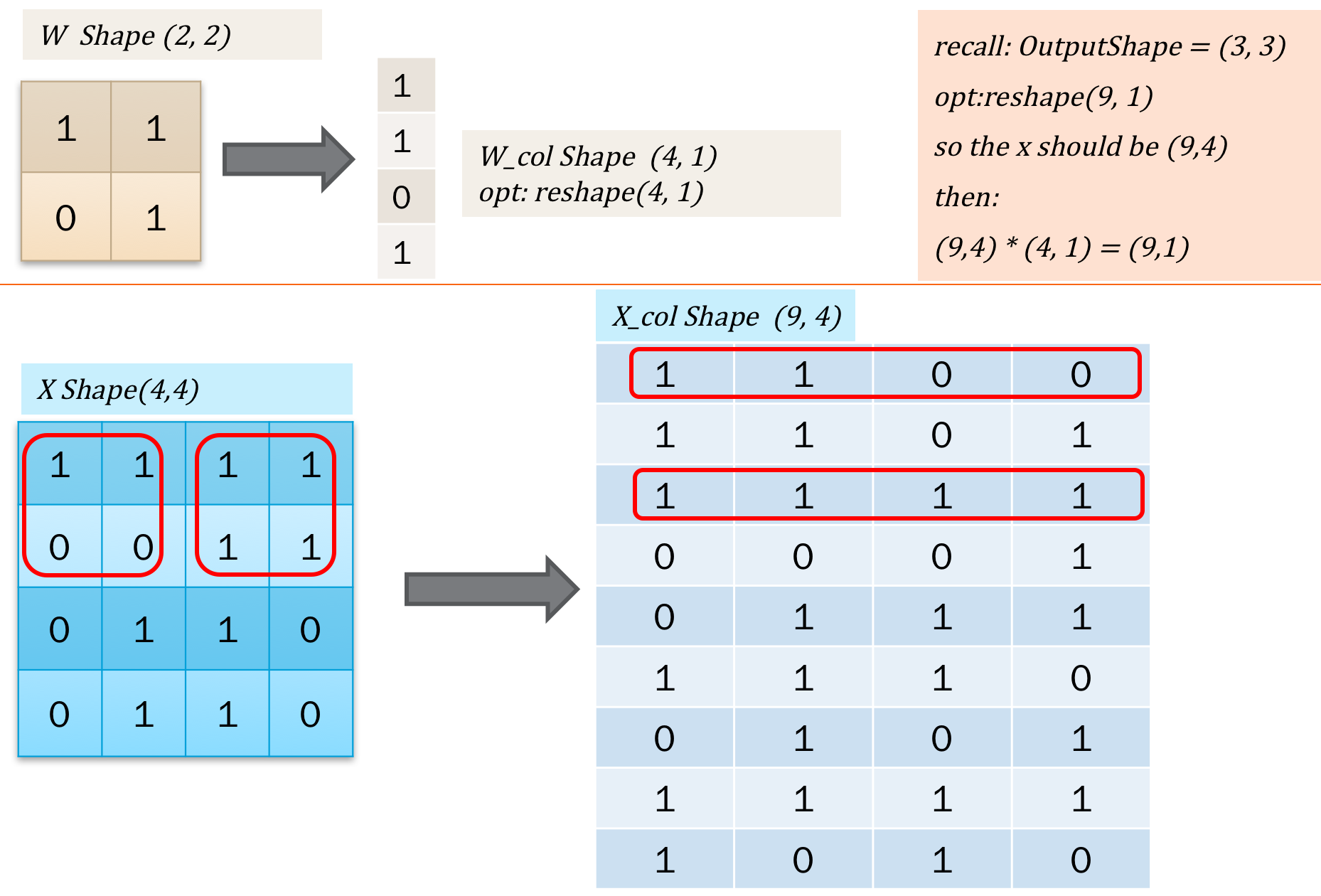 简单的说,就是把操作转为向量的形式。那么计算就和线性回归一样了,如下:
简单的说,就是把操作转为向量的形式。那么计算就和线性回归一样了,如下:
 对于误差反馈,我们还需要把反馈的误差,再转回到二维图像的形式,也就是col2im,如下图所示:
对于误差反馈,我们还需要把反馈的误差,再转回到二维图像的形式,也就是col2im,如下图所示:
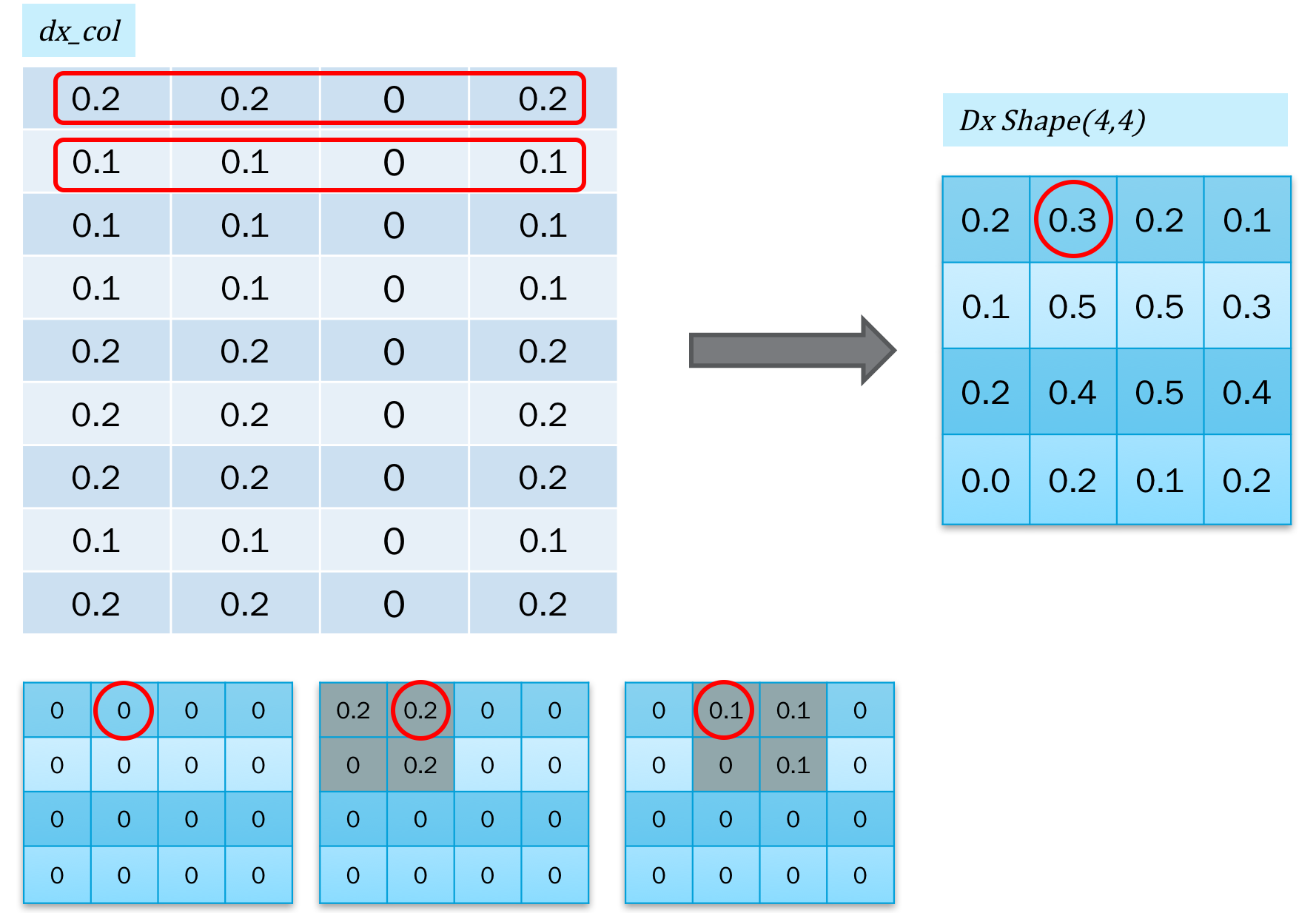 转换的时候,是不断的累加的。
转换的时候,是不断的累加的。
6、code
自己写了一个kitnet的神经网络库,最近比较忙,很多优化算法和layer还没实现。这里简单的给一下卷积的部分code。网上有很多好的代码值得参考和学习,这里就是配合上面的截图,给关键的几个函数。
class ConvLayer(ParamLayer):
def __init__(self, shape, pad_w=0, pad_h=0, stride=1,
name="ConvLayer", init_method="random", debug=0):
'''
shape (input_channel, filter_size, filter_size, output_channel)
c: channel
f: filter_size
b: batch_size
w: width
h: height
'''
super(ConvLayer, self).__init__(name, shape, init_method)
self.in_channel = shape[0]
self.filter_h = shape[1]
self.filter_w = shape[2]
self.out_channel = shape[3]
self.indx = self.filter_h * self.filter_w * self.in_channel
self.pad_h = pad_h
self.pad_w = pad_w
self.stride = stride
self.debug = debug
def forward(self, x):
'''
x shape: (batch_size, channel, height, weight)
'''
# get the output shape
self.batch_size, in_channel, in_h, in_w = x.shape
assert in_channel == self.in_channel
out_h = (in_h + 2 * self.pad_h - self.filter_h) / self.stride + 1
out_w = (in_w + 2 * self.pad_w - self.filter_w) / self.stride + 1
assert out_h % 1 == 0
assert out_w % 1 == 0
out_h, out_w = int(out_h), int(out_w)
# pad input array
x_padded = np.pad(x, ((0,0), (0,0), (self.pad_h, self.pad_h),
(self.pad_w, self.pad_w)), 'constant')
self.h_padded, self.w_padded = x_padded.shape[2], x_padded.shape[3]
# im2col, (out_h*out_w*batch_size, filter_h*filter_w*in_channel)
x_cols = None
for i in xrange(self.filter_h, self.h_padded+1, self.stride):
for j in xrange(self.filter_w, self.w_padded+1, self.stride):
for n in xrange(self.batch_size):
tmp = x_padded[n, :, i-self.filter_h:i, j-self.filter_w:j]
field = tmp.reshape((1, self.indx))
if x_cols is None:
x_cols = field
else:
x_cols = np.vstack((x_cols, field))
self.input = x_cols
# weight2col, (indx, out_channel)
self.w_cols = self.W.reshape(self.indx, self.out_channel)
# output_col shape, out_h*out_w*batch_size, out_channel
self.output_col = np.dot(self.input, self.w_cols) + self.b
# output shape, (batch_size, channel, height, weight)
self.output = self.output_col.reshape(self.batch_size, out_h,
out_w, self.out_channel)
if self.debug:
print "x_cols.shape = ", x_cols.shape
print "w_cols.shape = ", self.w_cols.shape
print "output.shape = ", self.output.shape
def backward(self, delta):
assert delta.size == self.output.size
delta_cols = delta.reshape(self.output_col.shape)
# grad_x_cols, (out_h*out_w*batch_size, indx)
grad_x_cols = np.dot(delta_cols, self.w_cols.T)
# get the grad
grad_w = np.dot(self.input.T, delta_cols)
grad_b = np.sum(delta_cols, axis=0)
self.grad =[grad_w.reshape(self.W.shape), grad_b.reshape(self.b.shape)]
# col2im: convert back from x_cols to x
# (batch_size, channel, height, weight)
dx_padded = np.zeros((self.batch_size, self.in_channel,
self.h_padded, self.w_padded))
idx = 0
tmp_shape = (1, self.in_channel, self.filter_h, self.filter_w)
for i in xrange(self.filter_h, self.h_padded+1, self.stride):
for j in xrange(self.filter_w, self.w_padded+1, self.stride):
for n in xrange(self.batch_size):
tmp = grad_x_cols[idx,:].reshape(tmp_shape)
dx_padded[n:n+1, :,
i - self.filter_h:i,
j - self.filter_w:j] += tmp
idx += 1
if self.pad_h == 0:
self.delta = dx_padded
else:
self.delta = dx_padded[:, :, self.pad_h:-self.pad_h,
self.pad_w:-self.pad_w]
# debug
if self.debug:
print "grad_w.shape = ", self.grad[0].shape
print "delta.shape = ", self.delta.shape