kaggle的比赛, 简单的说明一下,就是给定了一些数据,然后分成9类,涉及到的具体的特征是不清楚的,都用feat_1这种表示了,训练数据61878条,测试数据144368条。
目录
1、基本思路
数据读取的代码如下:
def load_train():
dpath = "data/train.csv"
data = pd.read_csv(dpath)
x = data.iloc[:, 1:-1]
x = x.values.copy().astype(np.float32)
y = [int(i.split("_")[-1]) for i in data.iloc[:, -1]]
encoder = LabelEncoder()
y = encoder.fit_transform(y)
return x, y
def load_test():
dpath = "data/test.csv"
data = pd.read_csv(dpath)
x = data.iloc[:, 1:]
x = x.values.copy().astype(np.float32)
return x
def submit_prob(y, name):
lens = y.shape[0]
f = open("Submission/" + name, "w")
head = ",".join(["Class_"+str(i+1) for i in xrange(9)])
f.write("id," + head + "\n")
for i in xrange(lens):
line = str(i + 1) + "," + ",".join(map(str, y[i])) + "\n"
f.write(line)
f.close()
这里随便用什么算法都可以,benchmark是用随机森林做的, 这里简单的给一下测试(本来是用cross-valid的方法,但是这里只是一些简单的做法,而且有些模型训练比较费时间,所以只随机分割一次,进行训练和测试)和benchmark的代码。
def test_model_onece(x, y, model):
x_train, x_test, y_train, y_test = cv.train_test_split(
x, y, test_size=0.2, random_state=123)
print("trainning...")
model.fit(x_train, y_train)
y_prob = model.predict_proba(x_test)
score = mt.log_loss(y_test, y_prob)
print("score: ", score)
return model
def base_line(x, y):
# x = np.log(x + 2)
model = ensemble.RandomForestClassifier(n_estimators=400, n_jobs=4)
name = "submit_rf_400_log.csv"
model.fit(x, y)
x_submit = load_test()
# x_submit = np.log(x_submit + 2)
y_submit = model.predict_proba(x_submit)
submit_prob(y_submit, name)
2、特征?
其实最开始的时候,我对数据做了一次description,发现这些数据是非常有偏的,而且是离散数据,比如某个feature中数值1出现的次数特别多,而大一点的数值出现的次数特别少。所以,我只做了一个特征变换x = np.log(x + 2),。
还有那些可以做的呢?在BMLSP_ch2_Classify_with_Real-world_Examples中,我是使用了一些特征之间的乘积作为新特征引入,提高准确率的。我在kaggle的论坛上,看到了大家的一些做法:
- 主流的是用XGB,现在用xgb,基本都能取得一个不错的成绩;
- 特征变换,这个是体力活,比如上面提到的取对数,以及各种特征组合,tf-idf特征等等。
- 使用t-SNE以及各种其他特征,比如sum of the row, number of non-zero, max of the row
这个做起来,相对比较无聊了。因为只要你用boosting的方法都能取得不错的成绩。另外,对于特征的处理,更加的无聊,一次次的尝试。如果机器性能不错,模型训练的比较快,那么你可以写一个循环,进行超参数的不断尝试。这里,大家还可以使用一下sklearn里的pipline的操作,可以各种合并和组合特征,以及模型。
3、看看第一名的做法
上面说的做法都是一般会采用的做法,而且top25的人们,一般都是用ensemble,而且是多种方法的融合。比如下图:
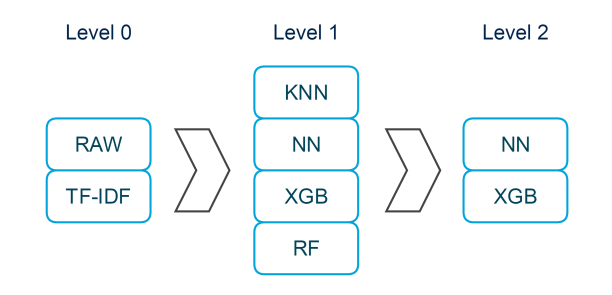
先做不同的特征变换,之后在每个特征上做一些模型,最后把这些模型进行融合。第一名的做法也是类似的,具体方法如下:
- 1st level:使用原始特征和一些特征工程,训练了33个模型。用这33个模型的输出和特征工程得到的8个特征,作为第二level的输入。之后再说一下这33个模型是什么。
- 2nd level:使用上面输出的结果作为特征,训练三个模型,分别是XGBOOST, Neural Network(NN) 和 ADABOOST with ExtraTrees。
- 3rd level:把level 2得到的预测结果作为输入,加权这些输出作为最终结果。(最后得到权重为 0.85 * [XGBOOST^0.65 * NN^0.35] + 0.15 * [ET])
看到这里,我对kaggle的比赛的感觉是————暴力求解。这里提到的33个模型中,有10个KNN模型(不同的k,有2、4、8、16、32、64、128、256、1024),还有两个KNN是在不同的特征上做的,此外还包括多个Xgboost模型、NN模型,T-sne,RandomForest, Logistic Regression等等模型,用到了R语言,python的 sklearn,theano,Lasagne 还有 H2O等等工具 。特征工程中,做了scale的归一化,log的变化, 开方的变化(比如sqrt( X + 3/8)),T-sne features降维的特征,甚至包括了kmean的聚类特征。 看一下第一名的also做的事情吧:
We tried a lot of training algorithms in first level as Vowpal Wabbit(many configurations), R glm, glmnet, scikit SVC, SVR, Ridge, SGD, etc… but none of these helped improving performance on second level. Also we tried some preprocessing like PCA, ICA and FFT without improvement. Also we tried Feature Selection without improvement. It seems that all features have positive prediction power. Also we tried semi-supervised learning without relevant improvement and we discarded it due the fact that it have great potential to overfit our results.
基本上各种试模型,不行的就换,稍微好一点的就留下来做ensemble。
4、做法
这种方式,确实可以打kaggle。但是,在实际工作中,有许多考量。虽然单个模型不是很复杂,但是维护起来很复杂!此外,各种模型的叠加,也不容易维护。更重要的是,训练模型的时间和预测一个样本所花费的时间,使得模型很难线上使用。
首先,层级化的模型训练是一种趋势,用随机森林或者xgb可以得到一个基本可用的模型,但是精度仍然是有限的。另外,使用图的结构来设计机器学习系统,会使得整个系统更直观,而且容易调整。此外, Sequential方式的模型,面临一定的挑战,graphic的模型,定制和灵活性更大。最后还是ensemble,把各个模型得到的结果整合一下,确实有提高。
我试过把NN和随机森林以及其他的模型组合起来,平均的组合起来也可以提升最后的结果,但是,最后还是不想训练太多模型,一个是没有那么多时间,一个是确实这个有点体力活。所以,我目前还是致力于使用一个模型,主要还是神经网络,通过不同的训练方式来得到更加鲁棒性和更准确的结果,我的主要思路主要有两个,一个是使用dropout,实现ensemble的效果;一个是,考虑训练数据是有限的,但是测试数据比训练数据大很多。实际工作中,也经常存在训练数据有限,而很多数据都没有标定。所以,如何把这些没有标定的数据利用起来,用于提高模型的准确率。比如通过autoencode模型,先自训练模型,得到一个更好的特征表达之后,在fine-tuning整个模型。这里做过一个实验,结果大概在0.48这样,跟最好的0.38还差0.1个点,大概在1000多名,跟直接使用NN+dropout的话,效果差不多。
另外,打kaggle也是自己学习一堆trick和培养数据感觉的一种很不错的方式!