本文主要是概述一下统计推断,涉及统计推断中的一些常用方法,包括置信区间、假设检验等。
目录
统计学有两个大模块,一个是描述统计、一个是统计推断。后者在计算机科学中称为“学习”,是指利用数据推断产生这些数据分布的过程,一个典型的统计推断问题是:给定样本\(X_1,X_2,...,X_n \sim F\),我们该怎样去推断F?而在某些情况下,我们只需要推断出F的某种性质即可,比如均值。 通常情况下F都是参数模型,比如服从参数为 \(\mu, \sigma\) 的正态分布。如果没有固定个数的参数,称之为非参数模型。(实际上,两者的定义非常复杂)
一般教材上都认为:估计(包括置信区间)和假设检验是统计推断两个主要方面。有很多方法来研究统计推断,主要的两个方法是古典的频率统计推断和贝叶斯推断(这里不细讲了)。 本文主要参考资料是《统计学完全教程》以及维基百科等相关内容。
1.概述
点估计
点估计是指对感兴趣的某一单点提供最优估计,感兴趣的点可以是参数模型、分布函数F、概率密度函数f和回归函数r等中的某一个参数,或者可以是对某些随机变量的未来值X的预测。点 \(\theta\)的点估计记为 \(\hat{\theta}\),这里的\(\theta\)是固定且未知的,而估计\(\hat{\theta}\)则是依赖于数据的,所以它是随机的。
估计一般要求满足无偏性,即估计量的偏差 \(bias(\hat{\theta}) = E_\theta(\hat{\theta}) - \theta\) 为0,则称是无偏估计。无偏性在以前备受关注,但是现在已经不被看重了。许多估计量都是有偏的,对估计量的一个合理要求是当收集的数据越来越多的时候,它将收敛于真实的参数值,即满足相合性(如果 \(\hat{\theta_n} \rightarrow^p \theta\), 则参数 \(\theta\)的点估计\(\hat{\theta}\)是相合的)。
\(\hat{\theta}\) 的分布称之为抽样分布,\(\hat{\theta}\) 的标准差称之为标准误se,通常标准误差依赖于未知分布F,在另外一些情况下,se是未知量,但通常需要去估计它,估计的标准误记为 \(\hat{se}\) 。点估计的质量好坏有时用均方误差(MSE)来评价:
\(MSE = E_\theta(\hat{\theta} - \theta)^2\) = \(bias^2(\hat{\theta_n}) + V_\theta(\hat{\theta_n})\) 。
附录:如果 \(\frac{\hat{\theta_n} - \theta}{se} \Rightarrow N(0,1)\), 则称估计量 \(\hat{\theta_n}\) 是渐进正态的(渐进分布是指某种特定分布的大样本性质,即在样本量足够大时的极限分布。)。
置信区间
参数 \(\theta\) 的1 - \(\alpha\) 置信区间 \(C_n = (a,b)\), 其中, \(a = a(X_1,...,X_n), b = b(X_1,...,X_n)\) 是数据的函数,满足 \(P_\theta(\theta \in C_n) \geq 1 - \alpha, \theta \in \Theta\) ,其含义为 \((a,b)\) 覆盖参数的概率为 \(1-\alpha\) ,称 \(1-\alpha\) 为置信区间的覆盖。 关于置信空间的解释,这里简单的提一句:对于95%的置信区间(\(1-\alpha\)),该区间不是对 \(\theta\) 的概率陈述,因为 \(\theta\) 是固定的而不是随机变量,一些教科书将置信区间解释如下:如果反复的重复试验,置信区间将有95% 的机会包括到参数。该解释没有错误,但是用处不大,因为人们很少反复的多次重复相同的试验。更好的解释是,第一次,对于参数 \(\theta_1\), 收集到数据并建立95%的置信区间;第二次、第三次…;对于这一系列不相关的参数\(\theta_i\), 建立置信区间,则这些置信区间有95%的概率覆盖真实的参数值。这一解释不需要反复的重复同一试验。
注意:\(C_n\)是随机的而\(\theta\)是固定的。置信区间只在频率统计中使用,在贝叶斯统计中的对应概念是可信区间。
点估计通常是具有极限正态分布的,即 \(\hat{\theta_n} \approx N(\theta,s\hat{e}^2)\), 在这种情况下,可以通过如下方式建立(近似)置信区间。
基于正态的置信区间:假设 \(\hat{\theta_n} \approx N(\theta,\hat{se}^2)\), 令 \(\Phi\) 为标准正态分布的CDF, \(z_\alpha/2 = \Phi^{-1}(1-(\alpha/2))\), 即\(P(Z>z_\alpha/2) = \alpha/2, P(-z_\alpha/2 < Z < z_\alpha/2) = 1- \alpha\), 其中 \(Z\) ~ \(N(0,1)\), 令\(C_n = (\hat{\theta_n}-z_{\alpha/2}\hat{se}, \hat{\theta_n}+z_{\alpha/2}\hat{se})\), 则\(P_\theta(\theta \in C_n) \rightarrow 1-\alpha\)
假设检验
在假设检验中,从缺省理论,即原假设开始,通过数据是否提供显著性证据来支持拒绝该假设,如果不能拒绝,则保留原假设。假设检验的基本思想是小概率反证法思想。小概率思想是指小概率事件(P<0.01或P<0.05)在一次试验中基本上不会发生。
这里,我们正式的定义一下,假设把参数空间 \(\Theta\) 分成两个不想交的集\(\Theta_0,\Theta_1\), 希望检验: \(H_0:\theta \in \Theta_0\) 对 \(H_1:\theta \in \Theta_1\),称 \(H_0\) 为原假设,\(H_1\)备择假设。令\(X\)为随机变量,令 \(\chi\) 为\(X\)的取值范围。通过找出称为拒绝域的适当子集 \(R \subset \chi\) 来检验假设。如果\(X \in R\), 则拒绝原假设,否则不能拒绝原假设(即保留原假设)。
通常,拒绝域\(R\)表达式为\(R = {x:T(x) \gt c}\), 其中T是检验统计量,c是临界值。假设检验的问题是找出恰当的检验统计量和恰当的临界值c.
注意:人们常常倾向于使用假设检验,尽管他们是不合适的。估计和置信区间常常是更好的工具。当想要检验一个定义完善的假设时,才会使用假设检验。
通常所说的假设检验是指奈曼-皮尔逊范式。如果原假设为真,而拒绝之成为类型\(I\)错误(弃真);类型\(I\)错误的概率称之为检验的显著性水平,通常记为\(\alpha\); 当原假设为假时而接受之称之为类型\(II\)错误(取谬),其概率通常记为\(\beta\);当原假设为假时而拒绝之的概率称之为检验的势,等于\(1-\beta\)。在一定样本量下,\(\alpha\)小,则\(\beta\)增大;\(\alpha\)大,则\(\beta\)小。为了同时减少\(\alpha\)和\(\beta\),只有增大样本容量,减小抽样分布的离散型,这样才能达到目的。\(\alpha\)和\(\beta\)的关系,可以通过正态分布的统计检验,如下图所示。
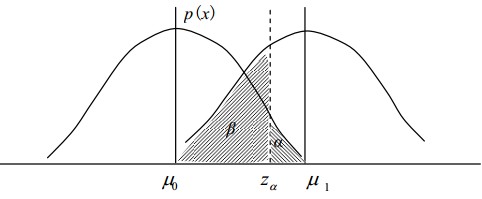 在显著性水平\(\alpha\)下,势函数最高的检验最好,这样的检验如果存在,则称为最强的检验。找出最强的检验很难,在本文中只介绍广泛使用的检验。
在显著性水平\(\alpha\)下,势函数最高的检验最好,这样的检验如果存在,则称为最强的检验。找出最强的检验很难,在本文中只介绍广泛使用的检验。
2.最大似然估计
背景
这里,我们暂且只关注参数模型,模型的形式为: \(\Xi = {f(x;\theta:\theta \in \Theta)}\), 其中\(\Theta \subset R^k\)是参数空间,\(\theta = (\theta_1,...,\theta_k)\), 因此推断问题简化为\(\theta\)的参数估计问题。那么怎么确定生成数据的分布是某种参数模型呢?实际上,很难知道这一点,这也是为什么非参数方法要更好的原因。但是,学习参数模型仍然非常有用。有两点原因:首先是我们可以根据案例的背景知识假定数据服从于某种参数模型,比如根据先验可以知道交通事故发生的次数近似服从泊松分布。其次,参数模型的推断概念为理解非参数方法提供了背景知识。
通常我们关心某一个函数\(T(\theta)\), 比如\(X\) ~ \(N(\mu,\sigma^2)\), 那么参数就是\(\theta=(\mu,\sigma)\), 如果目标是估计\(\mu\), 那么\(\mu=T(\theta)\) 就称为关注参数,而\(\sigma\)称为冗余参数。
在数理统计学中,似然函数是一种关于统计模型中参数的函数,表示模型参数中的似然性。“似然性”与“或然性”或“概率”意思相近,都是指某种事件发生的可能性,但是在统计学中,“似然性”和“或然性”或“概率”又有明确的区分。概率用于在已知一些参数的情况下,预测接下来的观测所得到的结果,而似然性则是用于在已知某些观测所得到的结果时,对有关事物的性质的参数进行估计。
最大似然估计
在参数模型中,最常用的参数估计方法是极大似然估计法。令\(X_1,...,X_N\) 独立同分布于概率密度函数\(f(x;\theta)\) 。似然函数定义为: \(L_n(\theta)= \prod_{i=0}^n f(X_i;\theta)\), 对数似然函数为\(l_n(\theta)=log(L_n(\theta))\), 似然函数并不是一个密度函数,一般而言,似然函数关于参数的积分并不等于1,最大似然估计函数不一定是惟一的,甚至不一定存在。
最大化似然函数的效果等同于最大化对数似然函数(计算方便)。最大化似然函数的思想是寻找合适的参数,使得已观测的事件发生的可能性最大。这里,就不在举例子了,可以参考维基百科:最大似然估计
最大似然估计性质
1.最大似然估计是相合估计:最大似然估计以概率收敛于真实值。
2.泛函不变性:如果\(\hat{\theta}是\theta\)的一个最大似然估计,那么\(\alpha=g(\theta)\) 的最大似然估计是\(\hat{\alpha}=g(\hat{\theta})\). 函数\(g\)无需是一个一一映射。
3.最大似然估计是渐进正态的,同事估计的标准差\(\hat{se}\)可以解出来。
4.最大似然估计是渐进最有或有效的,即在所有表现优异的估计中,最大似然估计的方差最小,至少对于大样本这肯定成立。
5.最大似然估计接近于贝叶斯估计。
附录:如果假设数据来自一个参数模型,那么最好应该检验这个假设。一种方法是通过检查数据的图形来非正式的检验这个假设条件,但需要注意你应该选择什么数据的图。
3.假设检验
假设检验是用来判断样本与样本,样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。其基本原理是先对总体的特征作出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受作出推断。
P值
1) 一种概率,一种在原假设为真的前提下出现观察样本以及更极端情况的概率,即检验统计量超过(大于或小于)由样本数据所得数值的概率。
2) 拒绝原假设的最小显著性水平。
3) 观察到的(实例的) 显著性水平。
4) 表示对原假设的支持程度,是用于确定是否应该拒绝原假设的另一种方法。
不同情况下检验选择
 用什么检验,依据的是中心极限定理.
中心极限定理中说,如果能够满足简单随机抽样具备30个样本容量,那么样本均值的抽样分布就是近似正态概率分布(注意不管总体服从什么分布);如果总体是正态概率分布的,不管简单随机抽样的样本是多少,样本均值的抽样分布都是正态概率分布.因此在你决定用什么检验的时候,首要考虑的条件是样本量,其次是总体是服从什么分布,然后因为样本均值的标准误(即样本均值抽样分布的标准差)的公式中需要知道总体的标准差,如果总体标准差知道,(无论大小样本,只是如果是小样本须满足总体要近似正态概率分布)都用Z检验;如果是大样本(n大于等于30),并且总体标准差未知,要用样本标准差去估计总体标准差(因为满足简单随机抽样,样本标准差总是总体标准差的无偏估计),然后还是用z分布做区间估计和假设检验;当样本量小于30,如果满足总体近似服从正态概率分布,如果总体标准差未知,可以用样本标准差去估计总体标准差,由此可用t分布做区间估计和假设检验。现在的软件简化了上述步骤,如果总体标准差已知(无论样本大小),都用z分布;只要总体标准差未知,全都用t分布。
用什么检验,依据的是中心极限定理.
中心极限定理中说,如果能够满足简单随机抽样具备30个样本容量,那么样本均值的抽样分布就是近似正态概率分布(注意不管总体服从什么分布);如果总体是正态概率分布的,不管简单随机抽样的样本是多少,样本均值的抽样分布都是正态概率分布.因此在你决定用什么检验的时候,首要考虑的条件是样本量,其次是总体是服从什么分布,然后因为样本均值的标准误(即样本均值抽样分布的标准差)的公式中需要知道总体的标准差,如果总体标准差知道,(无论大小样本,只是如果是小样本须满足总体要近似正态概率分布)都用Z检验;如果是大样本(n大于等于30),并且总体标准差未知,要用样本标准差去估计总体标准差(因为满足简单随机抽样,样本标准差总是总体标准差的无偏估计),然后还是用z分布做区间估计和假设检验;当样本量小于30,如果满足总体近似服从正态概率分布,如果总体标准差未知,可以用样本标准差去估计总体标准差,由此可用t分布做区间估计和假设检验。现在的软件简化了上述步骤,如果总体标准差已知(无论样本大小),都用z分布;只要总体标准差未知,全都用t分布。
详细的介绍,可以参考维基百科:Statistical hypothesis testing